Recent developments for the facial expression recognition problem consider processing the entire image regardless of the face crop location within the image. Such developments bring in extraneous artifacts, including noise,which might be harmful for classification as well as incur in unnecessary additional computational cost. This is problematic as the minutiae that characterizes facial expressions can be affected by elements such as hair, jewelry, and other environmental objects not defining the actual face and as part of the image background.
Four ResBlocks were used to extract high-dimensional features for image attention and to maintain spatial information; no pooling or strided convolutional layers were used.
使用4个ResBlocks来提取高维度特征,保留空间信息。如图所示。
Reconstruction Module
The reconstruction layer adjusts the attention map to create an enhanced input to the representation module. This module has two convolutional layers, a Relu layer, and an Average Pooling layer which, by design choice, resizes the input image of 128 × 128 to 32 × 32.
Representation and classification module
the network function, builds a representation for a sample image $x \\in R^D$ 主要是建立一个网络,对图片进行再表示,它的分类结果要与原图的分类结果足够接近。 详细过程参照论文,比较复杂。
损失函数
expriments
实验部分主要进行Rep模块的对照实验,数据集上的性能比较及算法对噪声的鲁棒性实验。
Datasets
Our image renderer R creates a synthetic larger dataset using real face datasets by making background changes and geometric transformations of face images.
现在的大部分研究关注的都是光照,姿态,遮挡等对表情识别的影响。作者关注的是个体差异像年龄,性别,种族背景等因素对表情识别的影响(the current main challenge comes from the large variations of individuals in attributes such as: age, gender, ethnic background and personality.)
Inspriation
people are capable of recognizing facial expressions by comparing a subject’s expression with a reference expression (i.e., neutral expression) of the same subject[1].
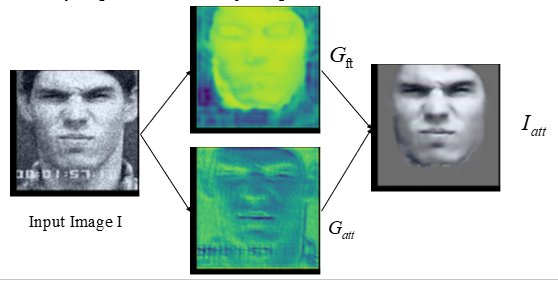
a facial expression can be decomposed to an expressive component and neutral component[2] 人们可以通过一个参考表情来识别其它表情(这里参考表情用的是中性表情);一个人脸表情可以分为中性部分和表情部分。如图所示。
cGAN[3]被用来从一个给定的图片生成一个中性人脸表情。 cGAN训练的输入是一个图像对$$,而生成器的输出为$I_{output}$。其中$I_{target}$是图片的中性表情的ground truth。$I_{output}$输出的是GAN生成的中性表情 The discriminator tries to distinguish the $< I_{input}, I_{target} >$ from the $< I_{input}, I_{output} >$ 判别器是为了尽力区分输出表情与ground truth之间的差别 the generator tries to not only maximally confuse the discriminator but also generate an image as close to the target image as possible. 而生成器则是尽可能使输出与ground truth足够接近,进而混淆视听。 Generator的目标函数 Discriminator的目标函数 cGAN的目标函数
拥有尽可能多的复杂环境的带标签的训练数据庥对于深度人脸表情识别系统的设计量至关重要的。在这一章,我们主要讨论那些包含基本表情,并广泛应用于深度学习算法评估的公共数据集。表X提供了这些数据集的概览。包含人的数量,图片或视频用例的数量,数据集收集的环境,表情的分布和其它信息。 表X 人脸表情数据集概览 CK+:CK+数据集是评估FER系统中应用最广泛的采集于实验室的数据集。CK+数据集包含来自123个人的593个视频序列,这些序列从10帧到60帧数量不等,并且展示出表情从中性到峰值的变化。这些视频序列都标有基于FACS的七个基本的表情标签(愤怒,蔑视,厌恶,害怕,高兴,悲伤,惊讶)。因为CK+并不提供特定的训练集,验证集和测试集,所有算法在这个数据集的评估方式存在差异,基于静态图片的最觉见的数据选取方法是提取每一个视频序列的第一帧,带有峰值信息的三帧及最后一帧。然后,将这些受试者被分成n组来进行n重交叉验证实验,通常选取的n值为5, 8, 10。 JAFFE:日本女性表情数集(JAFFE)是一个在实验室采集的图像数据集,其中包含来自10名日本女性的213张姿态表情。每一个人都有3-4张基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶),有一张中性的表情。由于该数据集拥有较少的图片,导致它具有一定的挑战性。 FER2013:FER2013数据集首次在ICML2013特征学习挑战赛中提出的。FER2013是使用谷歌图片搜索引擎自动收集的大规模,不受约束的数据集。所有的图片大小被调整到$48\times48$的。FER2013中包含28709张训练数据集,3589张验证数据集和3589张测试数据集,每张图片标注有七种标签(愤怒,厌恶,害怕,高兴,悲伤,惊讶和中性)之一。 AFEW:AFEW(Acted Facial Expression in the Wild)数据集自2013年起开始作为每年的EmotiW(Emotion Recognition in the Wild Challenge)的评测平台。AFEW包含来自不同的电影带有连续表情的电影片段,其中涉及姿态,遮挡和光照等复杂环境。每个样例标记有七个表情:愤怒,厌恶,恐惧,高兴,悲伤,惊讶和中性。表情的标签在持续更新,并有现实中的真人秀节目的数据不断增加进来。 EmotiW2017的AFEW 7.0数据集按照来自电影或真人秀的受试者将数据集分成三部分:训练集(773个),验证集(383个),测试集(653个)。 SFEW:SFEW(The Static Facial Expressions in the Wild)是基于脸部关键点计算关键帧从AFEW数据集中选取静态帧组成的。最常用的版本是SFEW2.0,其是EmotiW2015中SReco子挑战的基准数据集。SFEW2.0被分成三个数据集:训练数据集(958个),验证数据集(436个)和测试数据集(372个)。每张图片都被标记为七种表情种类(愤怒,厌恶,害怕,中性,高兴,悲伤和惊讶)的一种。 BU-3DFE:BU-3DFE(Binghamton University 3D Facial Expression)包含来自100个人的606个人脸表情序列。对于每张图片,都显式的标出6种基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶)的强度。和Multi-PIE相似,这个数据集通常被用于3D人脸表情分析。 Oulu-CASIA:Oulu-CASIA数据集包含来自80个个体共2880个视频序列,都标有六种基本表情标签:愤怒,厌恶,害怕,高兴,悲伤和惊讶等。环境为近红外光,可见光,三种不同的光照条件。同CK+数据集类似,它的第一帧是中性表情,最后一帧有峰值表情。特别是来自480个视频的最后三帧峰值表情和第一帧用来做10重交叉验证实验。 EmotionNet:EmotionNet是一个大型的数据集,它拥有100万张收自网络的人脸表情图片。其中的95万张图片用AU检测模型(action unit)来自动标注,剩下的25万张图片则是用11AUs去手动标注。在EmotinNet挑战赛上,提供了带有6种基本表情和10种综合表情标签的2478张图片。 RAF-DB:RAF-DB(Real-world Affective Face Database)是包含下载自互联网的29672张表情图片的真实世界的数据集。借助手动标注和可靠的估算,每个样例标有7个基本表情和11个综合表情标签。基本表情数据集中15339张图片被分成两组(12271个训练样例和3068个测试用例)用来评估算法性能。 AffectNet:AffectNet数据集包含来自网络的100多万张图片,每张图片使用不同的搜索引擎用与表情相关的关键字查询所获得。其中的45张图片已经被手式标注了8个基本表情标签。 ExpW:ExpW(Expression in-the-Wild Database)包含91793张使用google图片搜索引擎下载的人脸图片,每一张人脸的图片都被手动标注为7种基本表情的一种,无人脸的图片将在标注过程中移除掉。
由于 FER 研究将其主要关注点转移到具有挑战性的真实场景条件下,许多研究人员利用深度学习技术来解决这些困难,如光照变化、遮挡、非正面头部姿势、身份偏差和低强度表情识别。考虑到 FER 是一个数据驱动的任务,并且训练一个足够深的网络需要大量的训练数据,深度 FER 系统面临的主要挑战是在质量和数量方面都缺乏训练数据。由于不同年龄、文化和性别的人以不同的方式做出面部表情,因此理想的面部表情数据集应该包括丰富的具有精确面部属性标签的样本图像,不仅仅是表情,还有其他属性,例如年龄、性别、种族,这将有助于跨年龄、跨性别和跨文化的深度 FER 相关研究。另一方面,对大量复杂的自然场景图像进行精准标注是构建表情数据库一个明显的障碍。
#define MAX (1 << 30) intcal(string s, int beg, int end){//计算变成回文串的步数 int len = end - beg + 1, res = 0; if(len <= 0){ return0; } else{ for(int i = beg, j = end; i < beg + (end - beg + 1) / 2; ++i, --j){ if(s[i] != s[j]){ ++res; } } return res; } }
classSolution { public: intpalindromePartition(string s, int k){ int dp[105][105];//dp[i][j]表示将长为j的字符串分成i段 int len = s.size(); for(int i = 0; i <= 100; ++i){//初始化 for(int j = 0; j <= 100; ++j){ if(i >= j){ dp[i][j] = 0; } else{ dp[i][j] = MAX; } } } for(int i = 1; i <= k; ++i){//分段 for(int j = i; j <= len; ++j){//j的长度 for(int k = i - 1; k <= j; ++k){ dp[i][j] = min(dp[i][j], dp[i - 1][k] + cal(s, k, j - 1)); } } } return dp[k][len]; } };


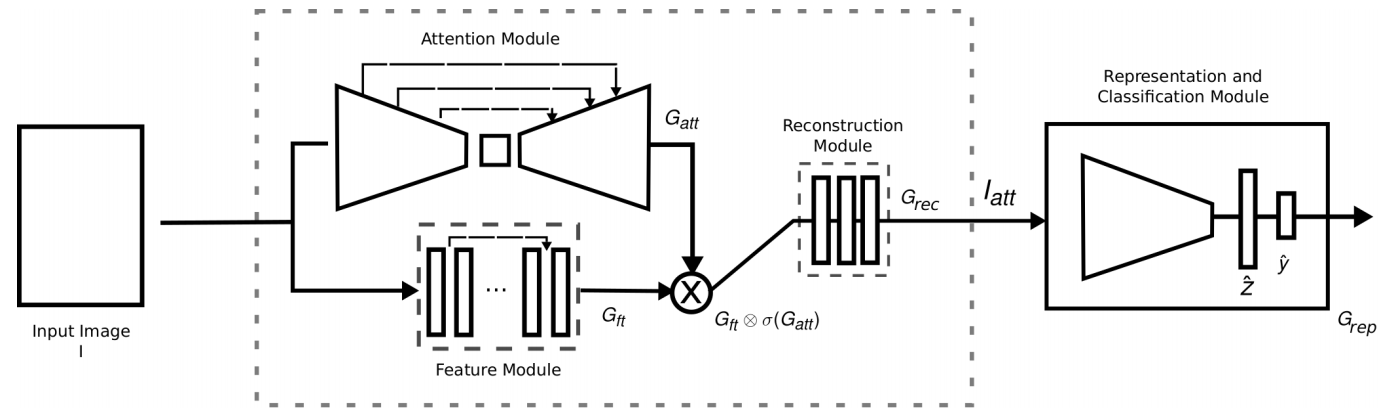
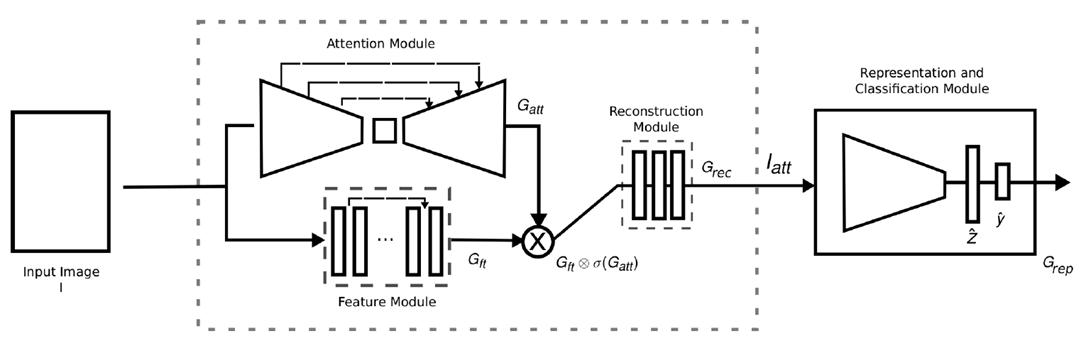 网络结构由4部分组成:注意力模块,特征提取模块,重建模块和分类表示模块。
网络结构由4部分组成:注意力模块,特征提取模块,重建模块和分类表示模块。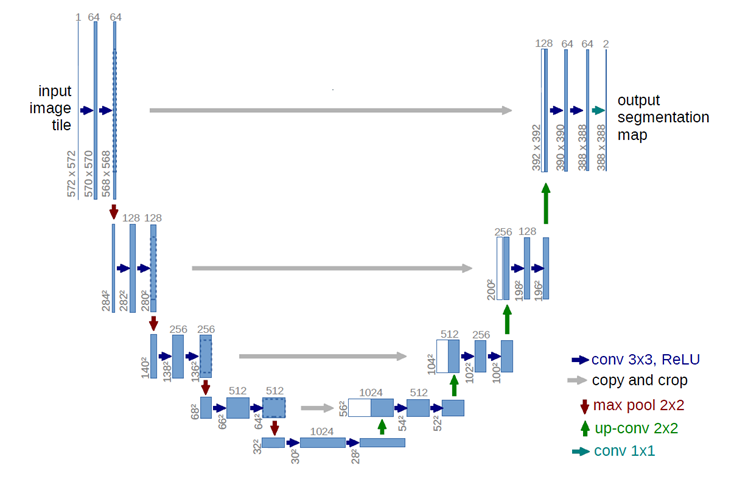 Attention模块将传统的人脸检测来用图像分割来代替。用了U-net来对图片进行分割,输出的是人脸的掩模。如图所示
Attention模块将传统的人脸检测来用图像分割来代替。用了U-net来对图片进行分割,输出的是人脸的掩模。如图所示 


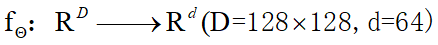 the network function, builds a representation for a sample image $x \\in R^D$ 主要是建立一个网络,对图片进行再表示,它的分类结果要与原图的分类结果足够接近。
the network function, builds a representation for a sample image $x \\in R^D$ 主要是建立一个网络,对图片进行再表示,它的分类结果要与原图的分类结果足够接近。 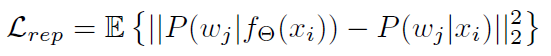 详细过程参照论文,比较复杂。
详细过程参照论文,比较复杂。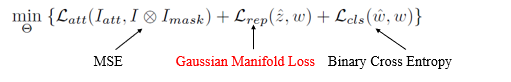
 使用的数据集有CK+、BU-3DFE、COCO dataset.其中COCO dataset 用作背景图。最后合成的数据集部分如图所示。
使用的数据集有CK+、BU-3DFE、COCO dataset.其中COCO dataset 用作背景图。最后合成的数据集部分如图所示。 
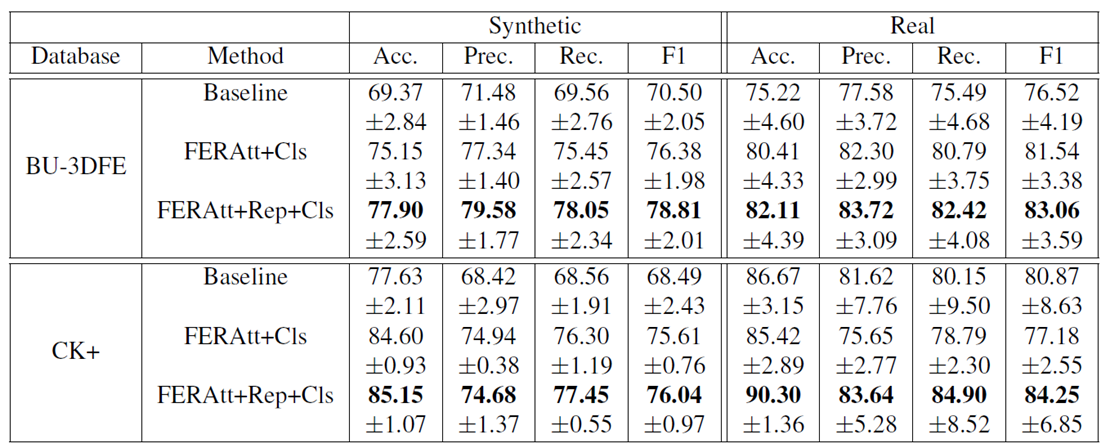 Baseline为PreActResNet18,将其与FERAtt+Cls 和FERAtt + Rep + Cls两种方法进行性能比较,发现再表示对性能的提升有明显的效果。
Baseline为PreActResNet18,将其与FERAtt+Cls 和FERAtt + Rep + Cls两种方法进行性能比较,发现再表示对性能的提升有明显的效果。 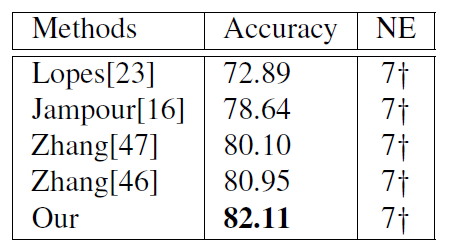

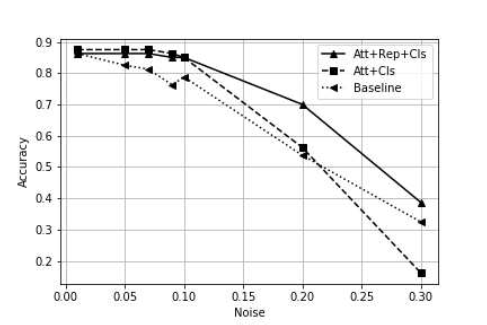
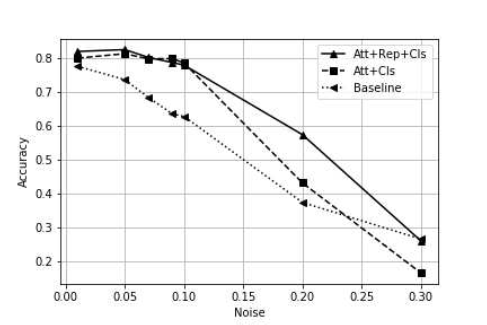 FERAtt + Rep + Cls算法对噪声的鲁棒性较好,在$\\sigma = 0 - 0.10$对于识别性能几乎无影响,继续增大$\\sigma$的值时,它的识别的精度也一直处于其它算法之上。
FERAtt + Rep + Cls算法对噪声的鲁棒性较好,在$\\sigma = 0 - 0.10$对于识别性能几乎无影响,继续增大$\\sigma$的值时,它的识别的精度也一直处于其它算法之上。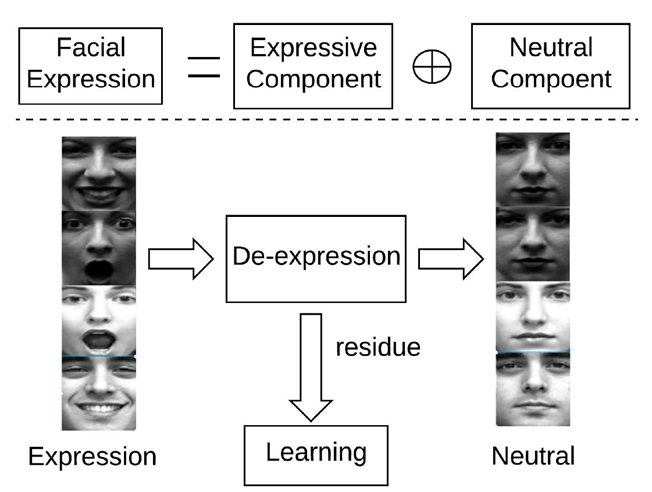
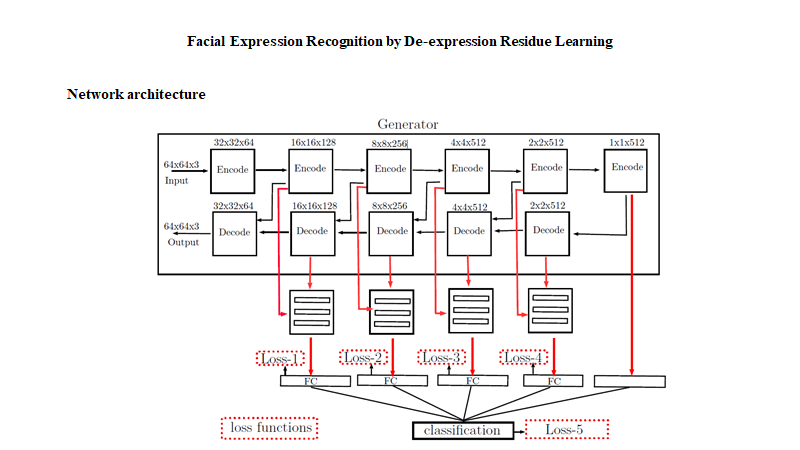 网络结构大体可分为两部分:GAN(Generator)用来生成中性表情,并保存有residue,用于训练学习;第二部分是学习残余特征,然后进行表情分类。 网络结构有很多细节没有体现,比如説学习残余特征的网络结构还有5个损失函数都没详细说明,论文中也没有细说。这里主要是学习的是它分解表情的思想。
网络结构大体可分为两部分:GAN(Generator)用来生成中性表情,并保存有residue,用于训练学习;第二部分是学习残余特征,然后进行表情分类。 网络结构有很多细节没有体现,比如説学习残余特征的网络结构还有5个损失函数都没详细说明,论文中也没有细说。这里主要是学习的是它分解表情的思想。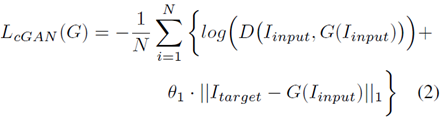 Discriminator的目标函数
Discriminator的目标函数 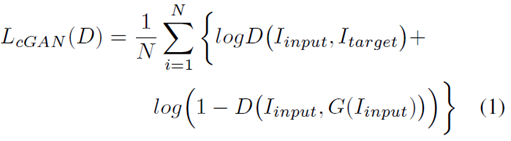 cGAN的目标函数
cGAN的目标函数 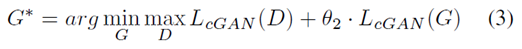
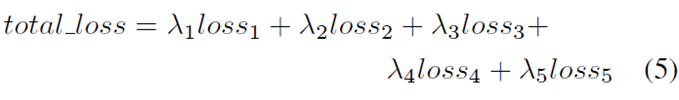 单个loss的系数大小取决于local classifier的表情分类效果
单个loss的系数大小取决于local classifier的表情分类效果 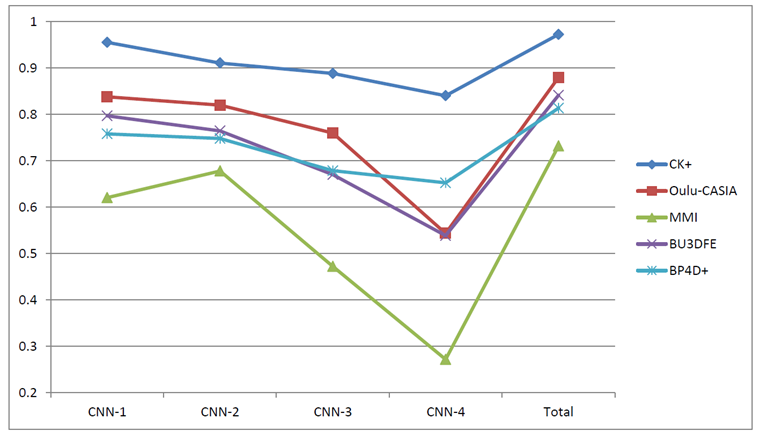
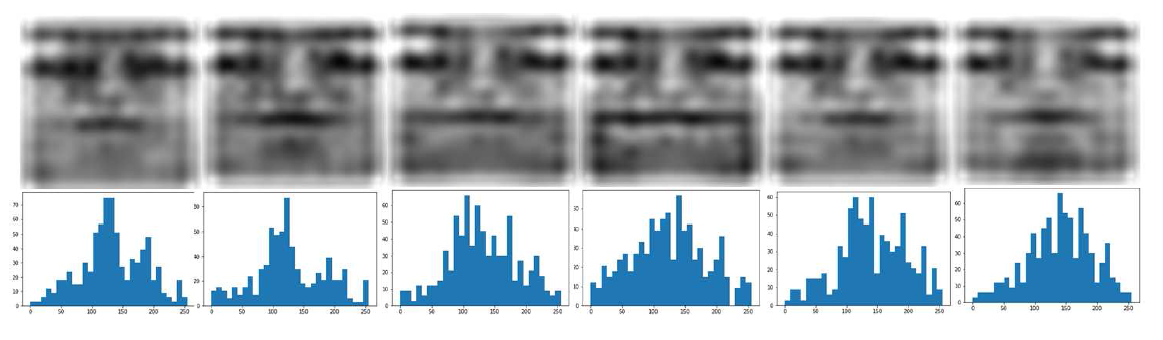 各个表情的残余特征可视化(从左到右是愤怒,厌恶,害怕,高兴,悲伤,惊讶)
各个表情的残余特征可视化(从左到右是愤怒,厌恶,害怕,高兴,悲伤,惊讶)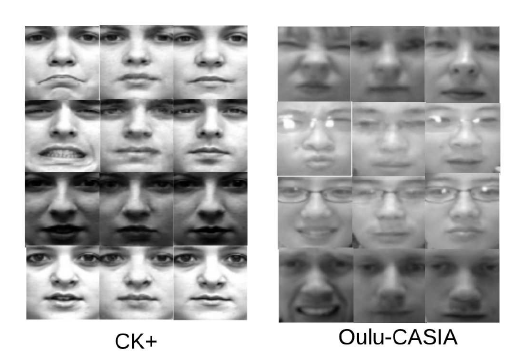
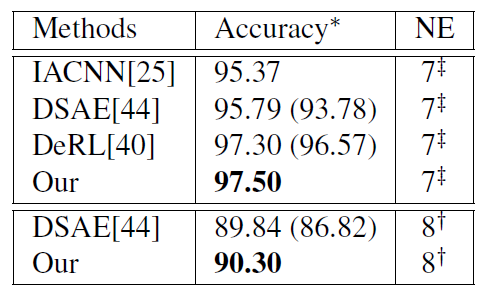
 CK+混淆矩阵
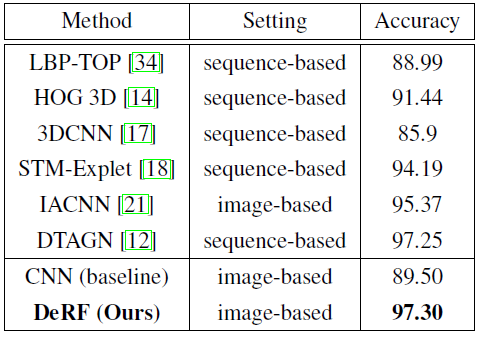
CK+混淆矩阵 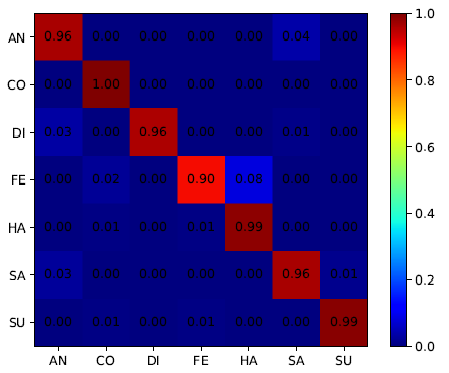 作者后面还在4个数据集上进行相同的实验,都取得比较好的性能,实验结果都处于前2的位置。
作者后面还在4个数据集上进行相同的实验,都取得比较好的性能,实验结果都处于前2的位置。 格局
格局 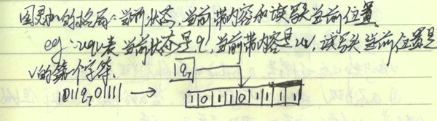 图灵可判定:有限步骤内,可知结果是yes或者no. 图灵可识别:有限步骤内,可知结果是yes.对于no的可能进入死循环. 图灵可补识别:有限步骤内,可知结果是no.对于yes的可能进入死循环. 识别语言$0^{2^n}$的图灵机如图.
图灵可判定:有限步骤内,可知结果是yes或者no. 图灵可识别:有限步骤内,可知结果是yes.对于no的可能进入死循环. 图灵可补识别:有限步骤内,可知结果是no.对于yes的可能进入死循环. 识别语言$0^{2^n}$的图灵机如图. 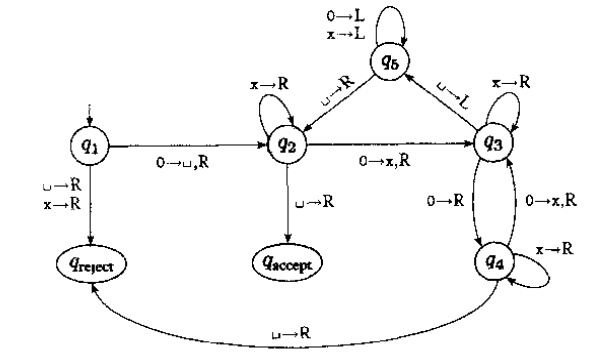 每次减半,直到1个0结束。中间出现奇数个0且不为1个,则进入拒绝态。
每次减半,直到1个0结束。中间出现奇数个0且不为1个,则进入拒绝态。 $A_{DFA}$显然可判定,因为DFA对于每个输入的串要不进入接受态,要不进入拒绝态。$E_{DFA}$采用的是标记法,类似于图中遍历。因为正则语言对于交,并,补运算都是封闭的,所以$EQ_{DFA}$可以转成$E_{DFA}$,而$ALL_{DFA}$又能转成$EQ_{DFA}$
$A_{DFA}$显然可判定,因为DFA对于每个输入的串要不进入接受态,要不进入拒绝态。$E_{DFA}$采用的是标记法,类似于图中遍历。因为正则语言对于交,并,补运算都是封闭的,所以$EQ_{DFA}$可以转成$E_{DFA}$,而$ALL_{DFA}$又能转成$EQ_{DFA}$  CFG的相关的可判定性问题,很大程度上依赖于乔姆斯基范式。$A_{CFG}$使用乔姆斯基范式能有限步内(2n-1步)判断能否识别某串。$A_{\epsilon CFG}$直接借用$A_{CFG}$可判定的结论,来判断是否能派生$\epsilon$串。$E_CFG}$可判定同样采用标记法,不过是逆向标记。
CFG的相关的可判定性问题,很大程度上依赖于乔姆斯基范式。$A_{CFG}$使用乔姆斯基范式能有限步内(2n-1步)判断能否识别某串。$A_{\epsilon CFG}$直接借用$A_{CFG}$可判定的结论,来判断是否能派生$\epsilon$串。$E_CFG}$可判定同样采用标记法,不过是逆向标记。 
 证明思路类似于$E_{CFG}$的证明.
证明思路类似于$E_{CFG}$的证明.
 证明$A_{TM}$不可判定,使用的是对角化方法。
证明$A_{TM}$不可判定,使用的是对角化方法。 

 前面提到的$0^n1^n$可以用上下文无关文法表示如下: $S\rarr 0S1\vert \epsilon$.
前面提到的$0^n1^n$可以用上下文无关文法表示如下: $S\rarr 0S1\vert \epsilon$.
 有些很难的CFG是在一些基础的CFG上发展来的,所以需要记住一些常见的CFG的形式。 一些常见的CFG表示如图所求.
有些很难的CFG是在一些基础的CFG上发展来的,所以需要记住一些常见的CFG的形式。 一些常见的CFG表示如图所求. 
 乔姆斯基范式有两个特点:一分为二;终级化. 将任意一个上下文无关文法转为乔姆斯基范式的步骤如下: 1. 引入新的起始变元 2. 删除$\epsilon$规则,相同的只替换一次,不循环替换 3. 去掉单一规则 4. 添加终结符规则 5. 添加新变元,使得所有变量规则都是一分为二 具体可参考65页的例3.7. 乔姆斯基范式有一个很重要的性质,在后面证$A_{CFG}$图灵可判定及多项式时间内判定某个串是否可以派生,都要用到乔姆斯基范式。因为乔姆斯基范式派生任何长为n的串,只需要$2n-1$步。
乔姆斯基范式有两个特点:一分为二;终级化. 将任意一个上下文无关文法转为乔姆斯基范式的步骤如下: 1. 引入新的起始变元 2. 删除$\epsilon$规则,相同的只替换一次,不循环替换 3. 去掉单一规则 4. 添加终结符规则 5. 添加新变元,使得所有变量规则都是一分为二 具体可参考65页的例3.7. 乔姆斯基范式有一个很重要的性质,在后面证$A_{CFG}$图灵可判定及多项式时间内判定某个串是否可以派生,都要用到乔姆斯基范式。因为乔姆斯基范式派生任何长为n的串,只需要$2n-1$步。 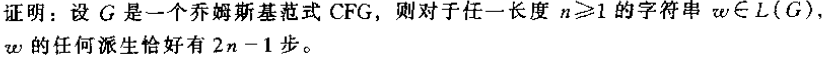 证明如图所求。
证明如图所求。 



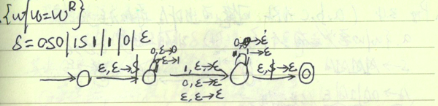

 “抽进”+“抽出”
“抽进”+“抽出”  注意:上下文 无关语言对并运算是封闭的,而对交,补,差都不是封闭的.
注意:上下文 无关语言对并运算是封闭的,而对交,补,差都不是封闭的. 注意:允许没有接受状态,此时接受语言为空集;转移函数对每一个状态和每一个可能的输入都恰好指定了一个状态。
注意:允许没有接受状态,此时接受语言为空集;转移函数对每一个状态和每一个可能的输入都恰好指定了一个状态。  定义正则运算的并、连结和星号
定义正则运算的并、连结和星号  正则运算的并,连结和星号都是封闭的,后面在证明DFA与NFA等价后,会用NFA对其进行证明。
正则运算的并,连结和星号都是封闭的,后面在证明DFA与NFA等价后,会用NFA对其进行证明。 c题含某子串,首先画出对应的子串,然后再判断其它输入的状态转换即可。 f题不含某个子串,首先画出含某个子串的DFA,然后将接受态转为非接受态,将非接受态转为接受态。这里运用了DFA的补是封闭这一性质。
c题含某子串,首先画出对应的子串,然后再判断其它输入的状态转换即可。 f题不含某个子串,首先画出含某个子串的DFA,然后将接受态转为非接受态,将非接受态转为接受态。这里运用了DFA的补是封闭这一性质。  对于l这种类型的题即DFA的或和且运算,画图比较麻烦,有时采用横1纵0不失为一种好方法。 对于n的倍数余m,首先画出n个状态围成的圈,然后从起始状态数起,将第m个状态标为接受态即可。对于这道题有个变形。画出长度除以3余2且除以4余1的DFA,这里先用中国剩余定理求出长度规律为$12n+5(n = 0, 1, \cdots,)$也就是画出长度除以12余5的DFA。 注意:DFA一般不能对保证串中字符a与字符b相等,如$a^nb^n$不是正则语言,通过后面学习知道它是上下无关语言。但是它能表示一个很特殊的串,即串中01和10子串个数相等,它等价于串以相同的字符开始和结尾。(可以把01和10想象成波形图中的下升与下降,现在下升段与下降段相等,那么开始与结尾的值一定相等,同为0或同为1),DFA如图。
对于l这种类型的题即DFA的或和且运算,画图比较麻烦,有时采用横1纵0不失为一种好方法。 对于n的倍数余m,首先画出n个状态围成的圈,然后从起始状态数起,将第m个状态标为接受态即可。对于这道题有个变形。画出长度除以3余2且除以4余1的DFA,这里先用中国剩余定理求出长度规律为$12n+5(n = 0, 1, \cdots,)$也就是画出长度除以12余5的DFA。 注意:DFA一般不能对保证串中字符a与字符b相等,如$a^nb^n$不是正则语言,通过后面学习知道它是上下无关语言。但是它能表示一个很特殊的串,即串中01和10子串个数相等,它等价于串以相同的字符开始和结尾。(可以把01和10想象成波形图中的下升与下降,现在下升段与下降段相等,那么开始与结尾的值一定相等,同为0或同为1),DFA如图。 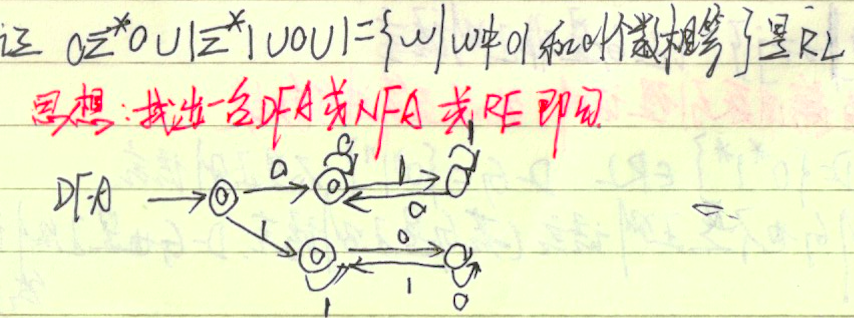

 与DFA的定义同为五元组,但仍存在一定差异。$\Sigma$中新增了$\epsilon$;$\delta$的映射结果属于状态集的幂集,即一入多出,同一个符号,可能对应多个状态转换。 注意:由于NFA加入非确定性,一个输入产生了多条路径,只要求所有路径中至少有一条路径能到达接受状态即可,这点与DFA也有所不同。
与DFA的定义同为五元组,但仍存在一定差异。$\Sigma$中新增了$\epsilon$;$\delta$的映射结果属于状态集的幂集,即一入多出,同一个符号,可能对应多个状态转换。 注意:由于NFA加入非确定性,一个输入产生了多条路径,只要求所有路径中至少有一条路径能到达接受状态即可,这点与DFA也有所不同。 已知$DFA\space A = \lbrace Q,\Sigma, \delta, q_0, F\rbrace$,现在要构造出一台与之对应的$NFA\space B = \lbrace Q^{\prime},\Sigma^{\prime}, \delta^{\prime}, q_0^{\prime}, F^{\prime}\rbrace$ 首先原来的DFA有n个状态,那NFA有$2^n$个状态(即状态的组合)$Q^{\prime} = \lbrace Q_{00\dots0}, Q_{10\dots0},\cdots,Q_{11\dots1}\rbrace$,$\Sigma^{\prime}$很简单就为$\lbrace0,1\rbrace$,$\delta^{\prime}$要随$Q^{\prime}$相应的改变,多个状态经过相同的输入的结果要进行位与,最后接受态$F^{\prime}$含有$2^{n-1}$即只是含$q_1$即可(第一个二进制位为1)。这样就构造出一台DFA与NFA对应。 即证DFA与NFA是等价的。
已知$DFA\space A = \lbrace Q,\Sigma, \delta, q_0, F\rbrace$,现在要构造出一台与之对应的$NFA\space B = \lbrace Q^{\prime},\Sigma^{\prime}, \delta^{\prime}, q_0^{\prime}, F^{\prime}\rbrace$ 首先原来的DFA有n个状态,那NFA有$2^n$个状态(即状态的组合)$Q^{\prime} = \lbrace Q_{00\dots0}, Q_{10\dots0},\cdots,Q_{11\dots1}\rbrace$,$\Sigma^{\prime}$很简单就为$\lbrace0,1\rbrace$,$\delta^{\prime}$要随$Q^{\prime}$相应的改变,多个状态经过相同的输入的结果要进行位与,最后接受态$F^{\prime}$含有$2^{n-1}$即只是含$q_1$即可(第一个二进制位为1)。这样就构造出一台DFA与NFA对应。 即证DFA与NFA是等价的。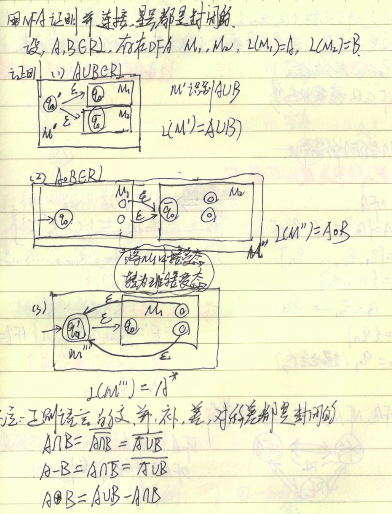 证明并运算,加入一个新的起始态,然后空漂到两台DFA的接受态即可。连接运算,将$M_1$中接受态全转为非接受态,然后将其空漂到$M_2$的起始态。星号运算,首先加入一个新的起始态(也是接受态)空漂到$M_1$的起始态,然后再将$M_1$的所有接受态空漂到新加入的起始态即可。
证明并运算,加入一个新的起始态,然后空漂到两台DFA的接受态即可。连接运算,将$M_1$中接受态全转为非接受态,然后将其空漂到$M_2$的起始态。星号运算,首先加入一个新的起始态(也是接受态)空漂到$M_1$的起始态,然后再将$M_1$的所有接受态空漂到新加入的起始态即可。
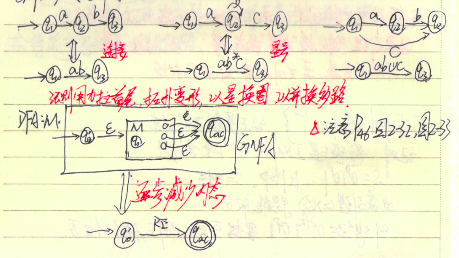 利用法则:用力拉首尾,拓扑变形,以星换圈,以并换多路,逐步减少内态。最后得到就是RE。具体可以参考书上46页的2张图。
利用法则:用力拉首尾,拓扑变形,以星换圈,以并换多路,逐步减少内态。最后得到就是RE。具体可以参考书上46页的2张图。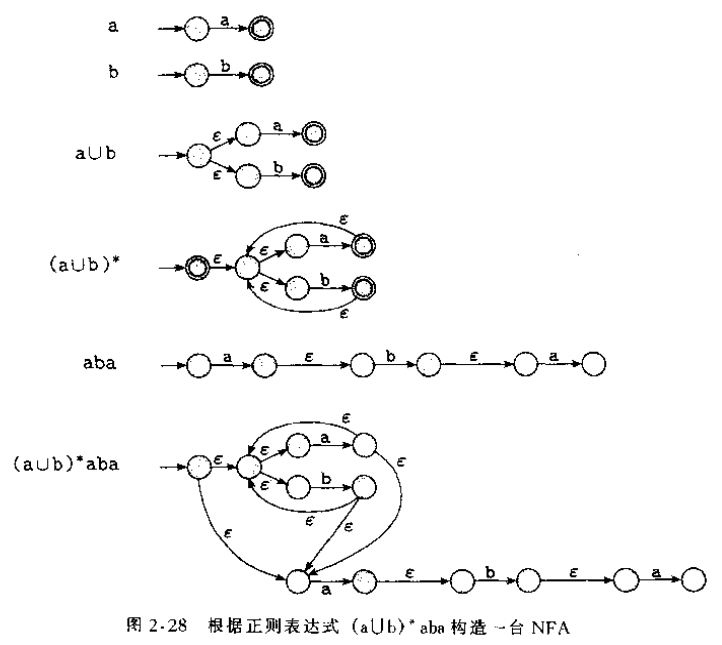 从最小的子表达式到大一点的子表达式逐步建立,直到获得关于原始表达式的NFA. 所以NFA与RE是等价的.
从最小的子表达式到大一点的子表达式逐步建立,直到获得关于原始表达式的NFA. 所以NFA与RE是等价的.


 另外证明$1^{n^2}$或者$1^{2^p}$这种形式语言,可以在序列中相邻两串长度间隔在不能增大作文章,因为长度间隔的离散性,一定不能满足任意抽取均能满足原语言。
另外证明$1^{n^2}$或者$1^{2^p}$这种形式语言,可以在序列中相邻两串长度间隔在不能增大作文章,因为长度间隔的离散性,一定不能满足任意抽取均能满足原语言。 成绩单
成绩单 
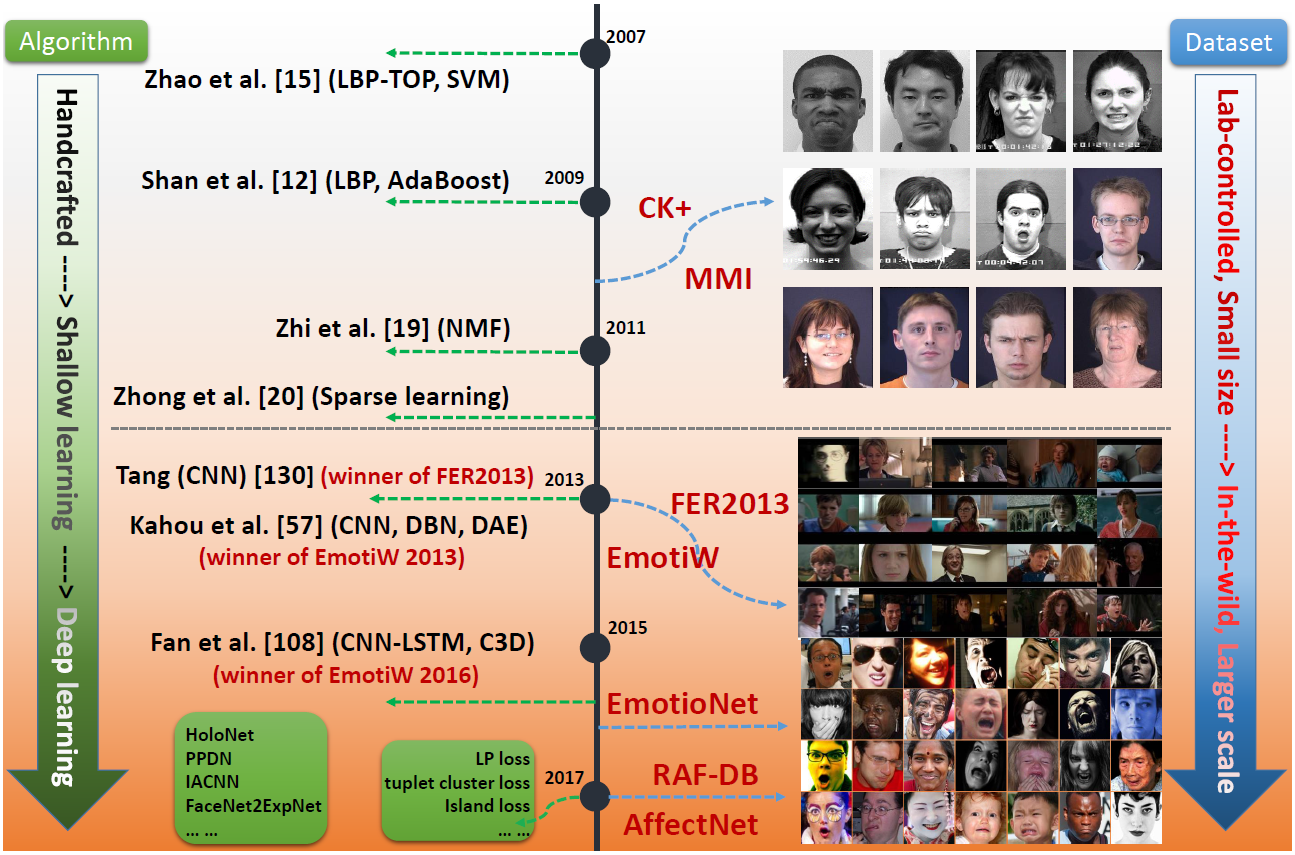 图X 人脸表情识别在数据集及方法上的演变 在这篇论文中,我们介绍一些用于解决以上问题的最新的深度FER的方法。首先,第2章介绍常用的人脸表情数据集,第3章介绍深度EFR系统中最主要的有三个步骤。……
图X 人脸表情识别在数据集及方法上的演变 在这篇论文中,我们介绍一些用于解决以上问题的最新的深度FER的方法。首先,第2章介绍常用的人脸表情数据集,第3章介绍深度EFR系统中最主要的有三个步骤。……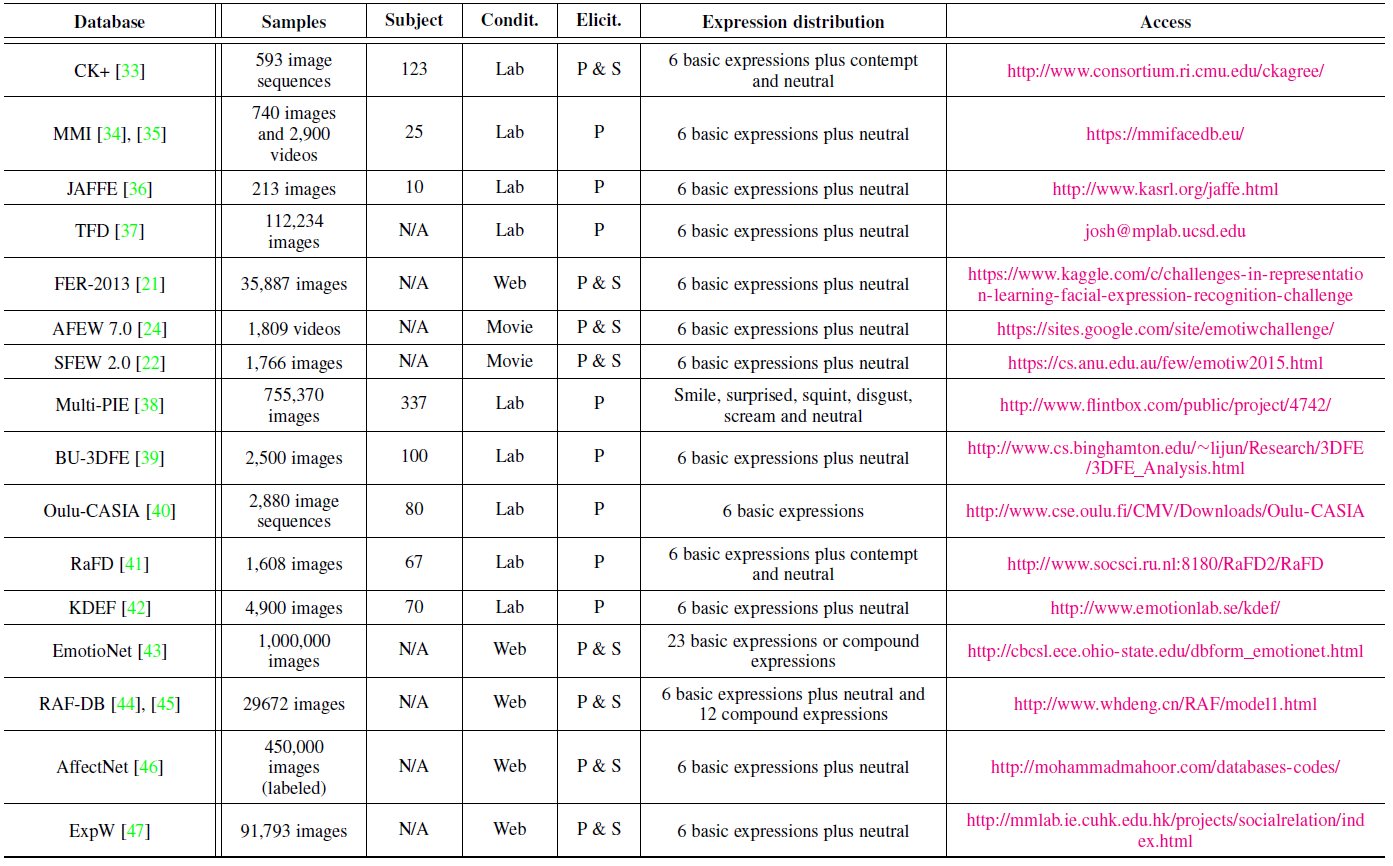 CK+:CK+数据集是评估FER系统中应用最广泛的采集于实验室的数据集。CK+数据集包含来自123个人的593个视频序列,这些序列从10帧到60帧数量不等,并且展示出表情从中性到峰值的变化。这些视频序列都标有基于FACS的七个基本的表情标签(愤怒,蔑视,厌恶,害怕,高兴,悲伤,惊讶)。因为CK+并不提供特定的训练集,验证集和测试集,所有算法在这个数据集的评估方式存在差异,基于静态图片的最觉见的数据选取方法是提取每一个视频序列的第一帧,带有峰值信息的三帧及最后一帧。然后,将这些受试者被分成n组来进行n重交叉验证实验,通常选取的n值为5, 8, 10。 JAFFE:日本女性表情数集(JAFFE)是一个在实验室采集的图像数据集,其中包含来自10名日本女性的213张姿态表情。每一个人都有3-4张基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶),有一张中性的表情。由于该数据集拥有较少的图片,导致它具有一定的挑战性。 FER2013:FER2013数据集首次在ICML2013特征学习挑战赛中提出的。FER2013是使用谷歌图片搜索引擎自动收集的大规模,不受约束的数据集。所有的图片大小被调整到$48\times48$的。FER2013中包含28709张训练数据集,3589张验证数据集和3589张测试数据集,每张图片标注有七种标签(愤怒,厌恶,害怕,高兴,悲伤,惊讶和中性)之一。 AFEW:AFEW(Acted Facial Expression in the Wild)数据集自2013年起开始作为每年的EmotiW(Emotion Recognition in the Wild Challenge)的评测平台。AFEW包含来自不同的电影带有连续表情的电影片段,其中涉及姿态,遮挡和光照等复杂环境。每个样例标记有七个表情:愤怒,厌恶,恐惧,高兴,悲伤,惊讶和中性。表情的标签在持续更新,并有现实中的真人秀节目的数据不断增加进来。 EmotiW2017的AFEW 7.0数据集按照来自电影或真人秀的受试者将数据集分成三部分:训练集(773个),验证集(383个),测试集(653个)。 SFEW:SFEW(The Static Facial Expressions in the Wild)是基于脸部关键点计算关键帧从AFEW数据集中选取静态帧组成的。最常用的版本是SFEW2.0,其是EmotiW2015中SReco子挑战的基准数据集。SFEW2.0被分成三个数据集:训练数据集(958个),验证数据集(436个)和测试数据集(372个)。每张图片都被标记为七种表情种类(愤怒,厌恶,害怕,中性,高兴,悲伤和惊讶)的一种。 BU-3DFE:BU-3DFE(Binghamton University 3D Facial Expression)包含来自100个人的606个人脸表情序列。对于每张图片,都显式的标出6种基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶)的强度。和Multi-PIE相似,这个数据集通常被用于3D人脸表情分析。 Oulu-CASIA:Oulu-CASIA数据集包含来自80个个体共2880个视频序列,都标有六种基本表情标签:愤怒,厌恶,害怕,高兴,悲伤和惊讶等。环境为近红外光,可见光,三种不同的光照条件。同CK+数据集类似,它的第一帧是中性表情,最后一帧有峰值表情。特别是来自480个视频的最后三帧峰值表情和第一帧用来做10重交叉验证实验。 EmotionNet:EmotionNet是一个大型的数据集,它拥有100万张收自网络的人脸表情图片。其中的95万张图片用AU检测模型(action unit)来自动标注,剩下的25万张图片则是用11AUs去手动标注。在EmotinNet挑战赛上,提供了带有6种基本表情和10种综合表情标签的2478张图片。 RAF-DB:RAF-DB(Real-world Affective Face Database)是包含下载自互联网的29672张表情图片的真实世界的数据集。借助手动标注和可靠的估算,每个样例标有7个基本表情和11个综合表情标签。基本表情数据集中15339张图片被分成两组(12271个训练样例和3068个测试用例)用来评估算法性能。 AffectNet:AffectNet数据集包含来自网络的100多万张图片,每张图片使用不同的搜索引擎用与表情相关的关键字查询所获得。其中的45张图片已经被手式标注了8个基本表情标签。 ExpW:ExpW(Expression in-the-Wild Database)包含91793张使用google图片搜索引擎下载的人脸图片,每一张人脸的图片都被手动标注为7种基本表情的一种,无人脸的图片将在标注过程中移除掉。
CK+:CK+数据集是评估FER系统中应用最广泛的采集于实验室的数据集。CK+数据集包含来自123个人的593个视频序列,这些序列从10帧到60帧数量不等,并且展示出表情从中性到峰值的变化。这些视频序列都标有基于FACS的七个基本的表情标签(愤怒,蔑视,厌恶,害怕,高兴,悲伤,惊讶)。因为CK+并不提供特定的训练集,验证集和测试集,所有算法在这个数据集的评估方式存在差异,基于静态图片的最觉见的数据选取方法是提取每一个视频序列的第一帧,带有峰值信息的三帧及最后一帧。然后,将这些受试者被分成n组来进行n重交叉验证实验,通常选取的n值为5, 8, 10。 JAFFE:日本女性表情数集(JAFFE)是一个在实验室采集的图像数据集,其中包含来自10名日本女性的213张姿态表情。每一个人都有3-4张基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶),有一张中性的表情。由于该数据集拥有较少的图片,导致它具有一定的挑战性。 FER2013:FER2013数据集首次在ICML2013特征学习挑战赛中提出的。FER2013是使用谷歌图片搜索引擎自动收集的大规模,不受约束的数据集。所有的图片大小被调整到$48\times48$的。FER2013中包含28709张训练数据集,3589张验证数据集和3589张测试数据集,每张图片标注有七种标签(愤怒,厌恶,害怕,高兴,悲伤,惊讶和中性)之一。 AFEW:AFEW(Acted Facial Expression in the Wild)数据集自2013年起开始作为每年的EmotiW(Emotion Recognition in the Wild Challenge)的评测平台。AFEW包含来自不同的电影带有连续表情的电影片段,其中涉及姿态,遮挡和光照等复杂环境。每个样例标记有七个表情:愤怒,厌恶,恐惧,高兴,悲伤,惊讶和中性。表情的标签在持续更新,并有现实中的真人秀节目的数据不断增加进来。 EmotiW2017的AFEW 7.0数据集按照来自电影或真人秀的受试者将数据集分成三部分:训练集(773个),验证集(383个),测试集(653个)。 SFEW:SFEW(The Static Facial Expressions in the Wild)是基于脸部关键点计算关键帧从AFEW数据集中选取静态帧组成的。最常用的版本是SFEW2.0,其是EmotiW2015中SReco子挑战的基准数据集。SFEW2.0被分成三个数据集:训练数据集(958个),验证数据集(436个)和测试数据集(372个)。每张图片都被标记为七种表情种类(愤怒,厌恶,害怕,中性,高兴,悲伤和惊讶)的一种。 BU-3DFE:BU-3DFE(Binghamton University 3D Facial Expression)包含来自100个人的606个人脸表情序列。对于每张图片,都显式的标出6种基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶)的强度。和Multi-PIE相似,这个数据集通常被用于3D人脸表情分析。 Oulu-CASIA:Oulu-CASIA数据集包含来自80个个体共2880个视频序列,都标有六种基本表情标签:愤怒,厌恶,害怕,高兴,悲伤和惊讶等。环境为近红外光,可见光,三种不同的光照条件。同CK+数据集类似,它的第一帧是中性表情,最后一帧有峰值表情。特别是来自480个视频的最后三帧峰值表情和第一帧用来做10重交叉验证实验。 EmotionNet:EmotionNet是一个大型的数据集,它拥有100万张收自网络的人脸表情图片。其中的95万张图片用AU检测模型(action unit)来自动标注,剩下的25万张图片则是用11AUs去手动标注。在EmotinNet挑战赛上,提供了带有6种基本表情和10种综合表情标签的2478张图片。 RAF-DB:RAF-DB(Real-world Affective Face Database)是包含下载自互联网的29672张表情图片的真实世界的数据集。借助手动标注和可靠的估算,每个样例标有7个基本表情和11个综合表情标签。基本表情数据集中15339张图片被分成两组(12271个训练样例和3068个测试用例)用来评估算法性能。 AffectNet:AffectNet数据集包含来自网络的100多万张图片,每张图片使用不同的搜索引擎用与表情相关的关键字查询所获得。其中的45张图片已经被手式标注了8个基本表情标签。 ExpW:ExpW(Expression in-the-Wild Database)包含91793张使用google图片搜索引擎下载的人脸图片,每一张人脸的图片都被手动标注为7种基本表情的一种,无人脸的图片将在标注过程中移除掉。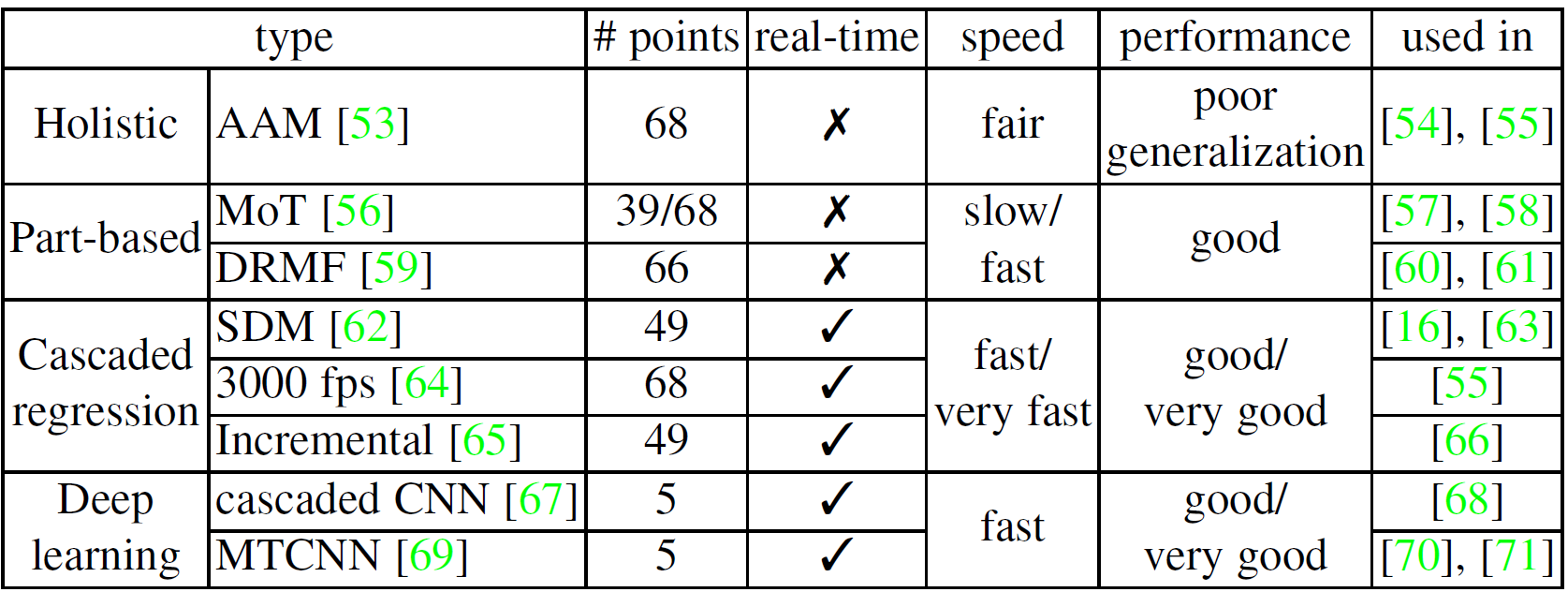 尽管人脸检测是特征学习前唯一的必不可少的过程,在检测后的人脸使用人脸对齐能进一步提高FER的性能。这一步是至关重要的,因为它能减小人脸规模和平面内旋转的变化。表X研究了广泛应用在深度FER中的人脸关键点检测算法并比较他们的执行效率及性能。主动外观模型(Active Appearance Model)是一个典型的生成式模型,优化全局的人脸外观和形状模型的参数。在判别式模型中,MoT(mixtures of trees)和DRMF(Disctiminative response map fitting)通过关键点周围的局部外观信息来表示人脸。另处,还有大量的差别式模型直接使用级联回归函数将图像外观特征映射到关键点位置,并显示更好的结果。比如在IntraFace中实现的SDM(supervised descent method),3000 fps和增量人脸对齐等等。最近,深度网络也广泛应用于人脸对齐。级联CNN是第一个用级联的方式来预测人脸关键点的深度算法。基于此,TCDCN(Tasks-Constrained Deep Convolutional Network)和多任务CNN(MTCNN)进一步利用多任务学习来提升性能。一般情况下,级联回归由于其高速和高精确度已经成为最流行和最新的算法。
尽管人脸检测是特征学习前唯一的必不可少的过程,在检测后的人脸使用人脸对齐能进一步提高FER的性能。这一步是至关重要的,因为它能减小人脸规模和平面内旋转的变化。表X研究了广泛应用在深度FER中的人脸关键点检测算法并比较他们的执行效率及性能。主动外观模型(Active Appearance Model)是一个典型的生成式模型,优化全局的人脸外观和形状模型的参数。在判别式模型中,MoT(mixtures of trees)和DRMF(Disctiminative response map fitting)通过关键点周围的局部外观信息来表示人脸。另处,还有大量的差别式模型直接使用级联回归函数将图像外观特征映射到关键点位置,并显示更好的结果。比如在IntraFace中实现的SDM(supervised descent method),3000 fps和增量人脸对齐等等。最近,深度网络也广泛应用于人脸对齐。级联CNN是第一个用级联的方式来预测人脸关键点的深度算法。基于此,TCDCN(Tasks-Constrained Deep Convolutional Network)和多任务CNN(MTCNN)进一步利用多任务学习来提升性能。一般情况下,级联回归由于其高速和高精确度已经成为最流行和最新的算法。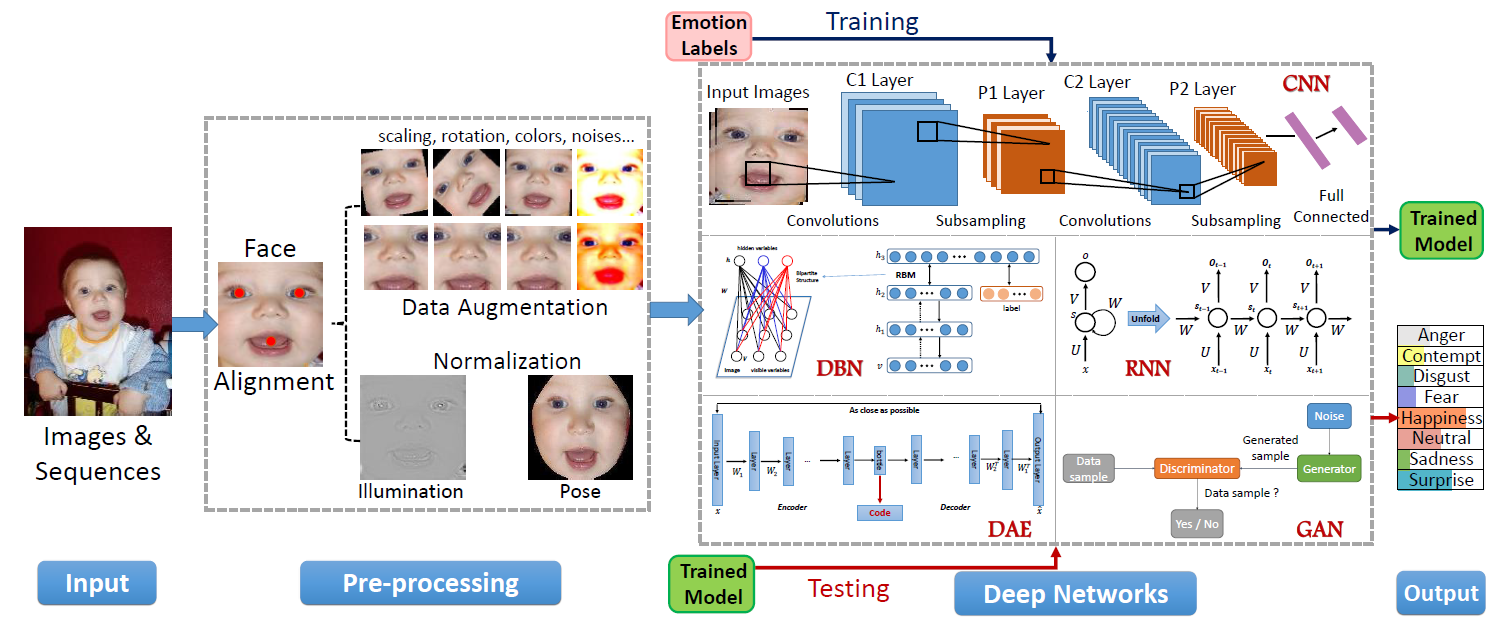 CNN在计算机视觉中广泛应用,一个CNN结构通常包含卷积层、池化层和全连接层等。在表X中我们列出了一些著名的CNN模型的构成和特征。除了这些神经网络,基于区域的CNN(R-CNN)也被用于FER中的特征学习,Faster R-CNN 通过生成高质量候选区域,识别面部表情。Ji et al提出的3D CNN通过3D卷积来对捕获多个相邻帧之间的动作信息来对动作进行识别。深度信念网络(DBN)是由Hinton提出的,学习提取训练数据的深度层次表示。DBN中,较高层的单元被训练去学习相邻低层的单元间的条件依赖,除了最高的两层,其余都没能直接连接。DBN的训练包含两个阶段:预训练和微调。首先用逐层贪婪训练方法初始化深度网络,可以在不需要大量标注数据的情况下防止局部最优解。然后,用有监督的梯度下降对网络的参数和输出进行微调。深度自编码器(Deep autoencoder)首次在[118]中提出来学习特征降维的有效编码,与之前的方法不同,DAE通过最小化重建误差来优化输入的重建。目前存在很多种DAE:降噪自编码器,可从部分损坏的数据中恢复原始未损坏数据;稀疏自编码网络,增强学习得到的特征表示的稀疏性;压缩式自编码器,增加活动相关正则项以提取局部不变特征;卷积自编码器,使用卷积层代替 DAE 中的隐藏层。循环神经网络(RNN)是联结主义的模型,能捕捉时间信息,对于任意长度的序列数据的预测是更合适的。时间的反向传播(BPTT)被用来训练RNN。由Hochreiter和Schmidhuber提出的LSTM是传统的RNN的一种特殊的形式被 用来解决常常出现在训练RNNs中的梯度消失和梯度爆炸的问题。LSTM能学习序列中的长时依赖,被广泛用于基于视频的表情识别的任务。
CNN在计算机视觉中广泛应用,一个CNN结构通常包含卷积层、池化层和全连接层等。在表X中我们列出了一些著名的CNN模型的构成和特征。除了这些神经网络,基于区域的CNN(R-CNN)也被用于FER中的特征学习,Faster R-CNN 通过生成高质量候选区域,识别面部表情。Ji et al提出的3D CNN通过3D卷积来对捕获多个相邻帧之间的动作信息来对动作进行识别。深度信念网络(DBN)是由Hinton提出的,学习提取训练数据的深度层次表示。DBN中,较高层的单元被训练去学习相邻低层的单元间的条件依赖,除了最高的两层,其余都没能直接连接。DBN的训练包含两个阶段:预训练和微调。首先用逐层贪婪训练方法初始化深度网络,可以在不需要大量标注数据的情况下防止局部最优解。然后,用有监督的梯度下降对网络的参数和输出进行微调。深度自编码器(Deep autoencoder)首次在[118]中提出来学习特征降维的有效编码,与之前的方法不同,DAE通过最小化重建误差来优化输入的重建。目前存在很多种DAE:降噪自编码器,可从部分损坏的数据中恢复原始未损坏数据;稀疏自编码网络,增强学习得到的特征表示的稀疏性;压缩式自编码器,增加活动相关正则项以提取局部不变特征;卷积自编码器,使用卷积层代替 DAE 中的隐藏层。循环神经网络(RNN)是联结主义的模型,能捕捉时间信息,对于任意长度的序列数据的预测是更合适的。时间的反向传播(BPTT)被用来训练RNN。由Hochreiter和Schmidhuber提出的LSTM是传统的RNN的一种特殊的形式被 用来解决常常出现在训练RNNs中的梯度消失和梯度爆炸的问题。LSTM能学习序列中的长时依赖,被广泛用于基于视频的表情识别的任务。 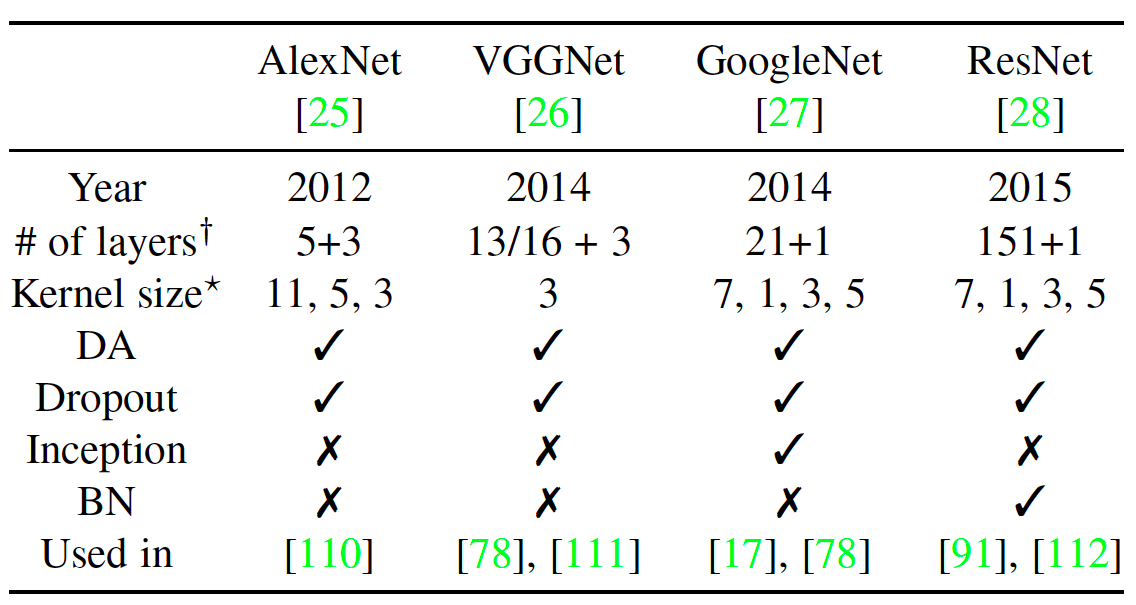
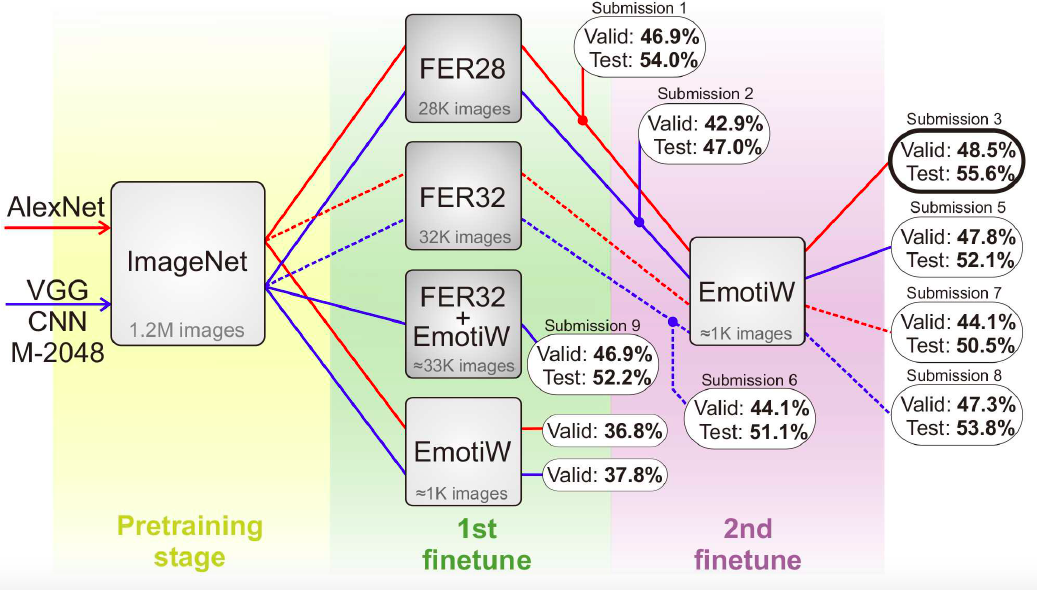 Ding 等人发现由于 FR 和 FER 数据库之间的差距,人脸主导的信息仍然遗留在微调的 FR 网络中,削弱了网络表示不同表情的能力。提出FaceNet2ExpNet的训练策略,如图X所示。微调的网络作为表情网络的初始值,仅能引导卷积层的学习,全连接层的训练则从头开始。
Ding 等人发现由于 FR 和 FER 数据库之间的差距,人脸主导的信息仍然遗留在微调的 FR 网络中,削弱了网络表示不同表情的能力。提出FaceNet2ExpNet的训练策略,如图X所示。微调的网络作为表情网络的初始值,仅能引导卷积层的学习,全连接层的训练则从头开始。 FSN(Feature Selection Network)是在AlexNet中加入了一个特征选择机制,它能自动过滤掉不相关特征,然后根据对人脸表情特征图的学习突出相关特征。Zeng et al.提出了IPA2LT(Inconsistent Pseudo Annotations to Latent Truth)结构,它通过将人类标注与机器标注最大似然化来发现不同数据集间机器的潜在真值。Cai 等人提出岛损失层。如图X所求。特征提取层计算的岛损失层和决策层计算的 softmax 损失结合起来监督 CNN 训练。Liu 等人提出(N+M)组聚类损失层。如图X所求在训练过程中,身份感知的难分样本挖掘和积极样本挖掘技巧用于降低同一表情类别下身份内部的变化所带来的影响。 图X [140]中的岛损失层
FSN(Feature Selection Network)是在AlexNet中加入了一个特征选择机制,它能自动过滤掉不相关特征,然后根据对人脸表情特征图的学习突出相关特征。Zeng et al.提出了IPA2LT(Inconsistent Pseudo Annotations to Latent Truth)结构,它通过将人类标注与机器标注最大似然化来发现不同数据集间机器的潜在真值。Cai 等人提出岛损失层。如图X所求。特征提取层计算的岛损失层和决策层计算的 softmax 损失结合起来监督 CNN 训练。Liu 等人提出(N+M)组聚类损失层。如图X所求在训练过程中,身份感知的难分样本挖掘和积极样本挖掘技巧用于降低同一表情类别下身份内部的变化所带来的影响。 图X [140]中的岛损失层 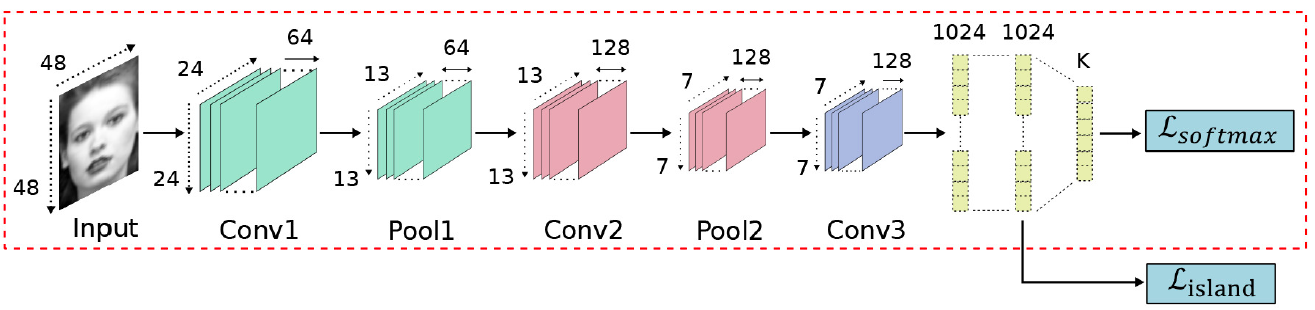 图X [77]组聚类损失层
图X [77]组聚类损失层 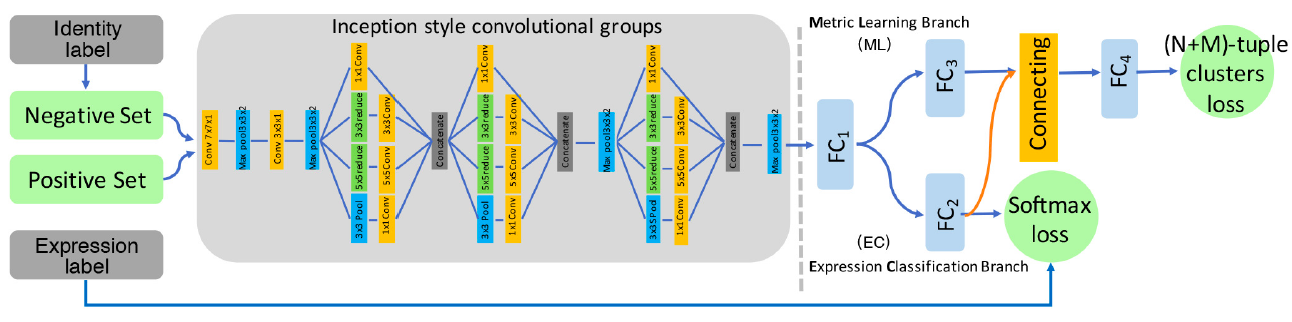
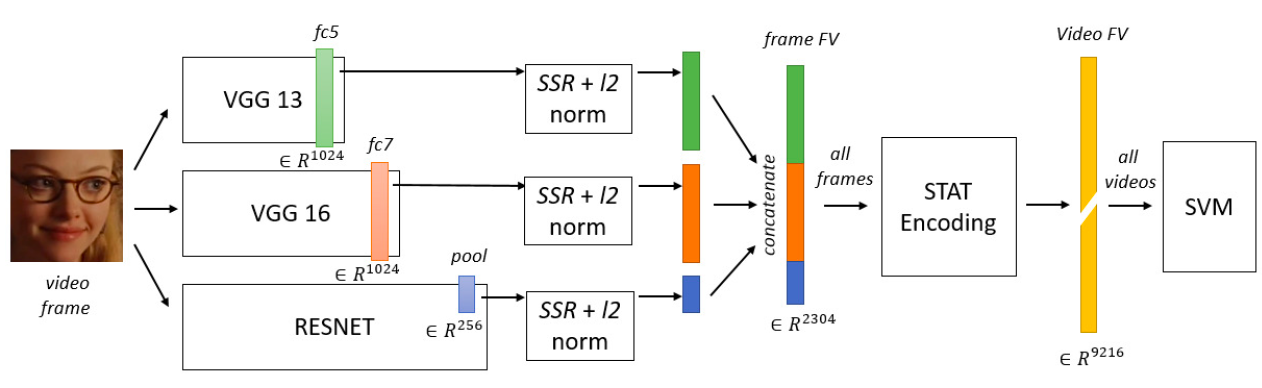
 现在的很多研究,都是整张进行处理,引入噪声和不必要的计算。仿照人的注意力机制,Fernandez等人提出了一种注意力网络,如图X所求。共分为四个模块:注意力模块、特征提取模块、重建模块和分类再表示模块。并设计出高斯损失函数来优化特征表示。针对遮挡和姿态两大难题,Kai Wang等在FERplus,AffectNet、RAF-DB三个数据集的基础上筛选遮挡和姿态较大的图片创建了六个数据集Occlusion-FERPlus, Pose-FERPlus, Occlusion-AffectNet, Pose-AffectNet, Occlusion-RAF-DB, and Pose-RAF-DB。并设计出RAN(Region Attention Networks),如图X所求。并设计了RB-Loss,来提升区域在特征表示上的权重。该方法在多个数据集均有较大的性能提升。陆续将会有更多基于Attention机制的FER网络被提出,它在某些问题上的性能表现优于一般的网络结构。 图X RAN网络结构
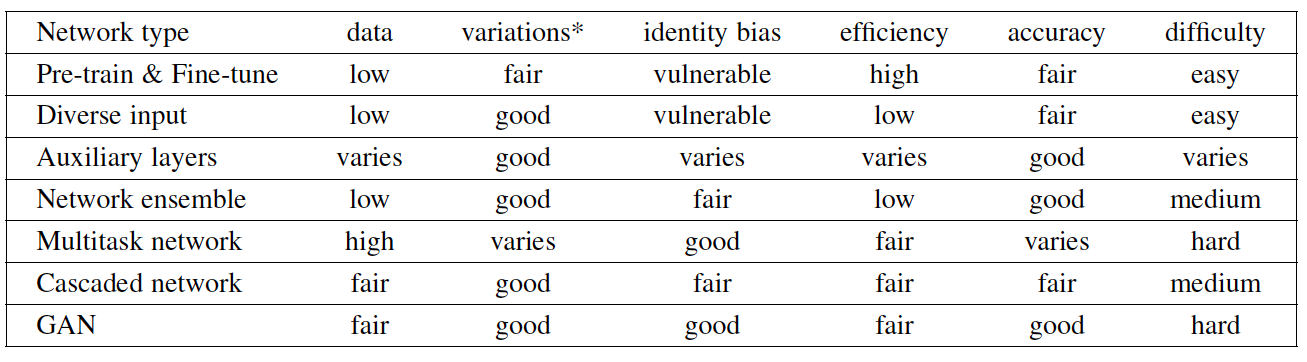
现在的很多研究,都是整张进行处理,引入噪声和不必要的计算。仿照人的注意力机制,Fernandez等人提出了一种注意力网络,如图X所求。共分为四个模块:注意力模块、特征提取模块、重建模块和分类再表示模块。并设计出高斯损失函数来优化特征表示。针对遮挡和姿态两大难题,Kai Wang等在FERplus,AffectNet、RAF-DB三个数据集的基础上筛选遮挡和姿态较大的图片创建了六个数据集Occlusion-FERPlus, Pose-FERPlus, Occlusion-AffectNet, Pose-AffectNet, Occlusion-RAF-DB, and Pose-RAF-DB。并设计出RAN(Region Attention Networks),如图X所求。并设计了RB-Loss,来提升区域在特征表示上的权重。该方法在多个数据集均有较大的性能提升。陆续将会有更多基于Attention机制的FER网络被提出,它在某些问题上的性能表现优于一般的网络结构。 图X RAN网络结构 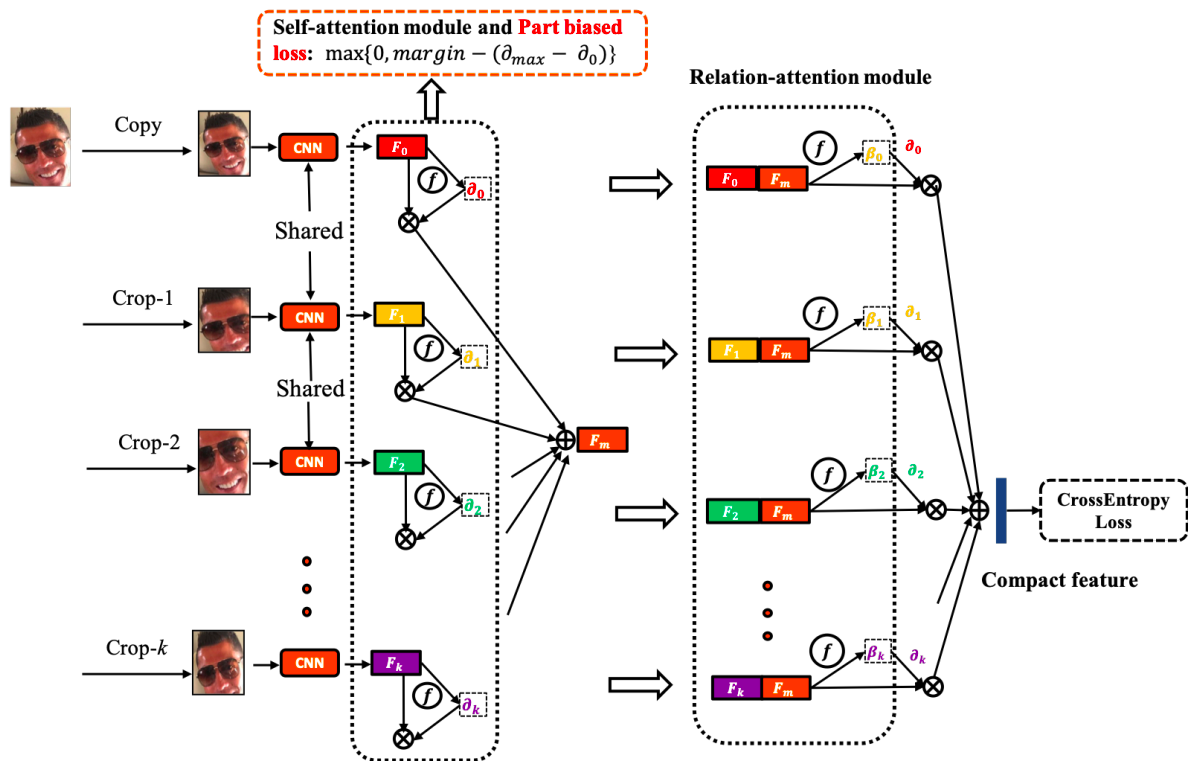 表X比较了不同类型的方法(预处理微调,辅助层,网络集成,多任务网络,注意力网络)对于数据大小的要求,在复杂环境(头的姿态,光照,遮挡和其它环境因素)的性能,计算效率,准确率,网络训练的难度。
表X比较了不同类型的方法(预处理微调,辅助层,网络集成,多任务网络,注意力网络)对于数据大小的要求,在复杂环境(头的姿态,光照,遮挡和其它环境因素)的性能,计算效率,准确率,网络训练的难度。