深度静态人脸表情识别综述阅读笔记
1 引言
人脸表情是人们用来表达情感的最有力,最自然和最普通的方式之一。由于人脸表情识在社交机器人,医学治疗,疲劳驾驶检测和许多人机交互系统的实际应用价值,已经做了很多关于人脸表情识别的研究。早在20世纪,Ekman和Friesen基于人们对于相同表情的表达与种族无关的研究,定义了六种基本的表情。包括愤怒,厌恶,害怕,高兴,悲伤和惊讶。蔑视后来也被加入基本表情中。 尽管基于基本表情的模型在表达人们日常生活中的复杂表情和细微表情上的能力有所不足,像面部动作编码系统(FACS)等可以表示更宽范围,更丰富的表情。但基于基本表情的分类模型仍是FER中最流行的,在这篇综述中,我们也仅在这种分类模型上讨论FER。 FER系统可以根据特征表示被分成两个主要类别:静态图像FER和动态序列FER。在基于静态的方法其特征表示的编码仅包含单个图像的空间信息,而基于动态的方法的特征表示的编码考虑了输入表情序列的连续帧之间的时间关系。用于FER的大多数传统的方法使用的是手工特征或浅层学习(例如,局部二元模式(LBP),非负矩阵分解(NMF)和稀疏学习)。然而,自从2013年起,表情识别比赛,如FER2013和EmotiW,从现实的场景中,收集足够多的训练数据,促使FER从实验室走向实际场景。与此同时,由于芯片的处理能力的急速提高(例如,GPU)和好的网络架构,使得各个领域的研究已开始转移到深度学习的方法,取得了最好的识别精度并且大幅度超过传统方法的识别精度。在表情识别方面,近年来,相关的研究机构也提供了大量的训练数据集,越来越多的深度学习的方法被提出来解决表情识别中一些具有挑战的场景。在图1展示出的Fer相关的算法和数据集的演变。 近年来,关于人脸表情识别的综述有很多,这些综述建立了一系列关于FER的标准算法准则,但是,他们集中于对传统方法的论述,对深度方法很少提及。因此,在这篇文章,对基于静态单张图片的FER任务的深度方法进行了全面的研究。尽管深度学习具有强大的特征学习能力,但应用到FER仍然还存在着一些问题。首先,深度神经网络需要大量的训练数据来防止过拟合,然而,现存在的人脸表情数据集不够充分以致不能训练较好的神经网络模型。另外,由于不同人的年龄,性别,种族背景等导致个体间存在较大的差异。除了个体差异,光照、遮挡和姿态等因素对于人脸表情识别的性能具有较大的影响。 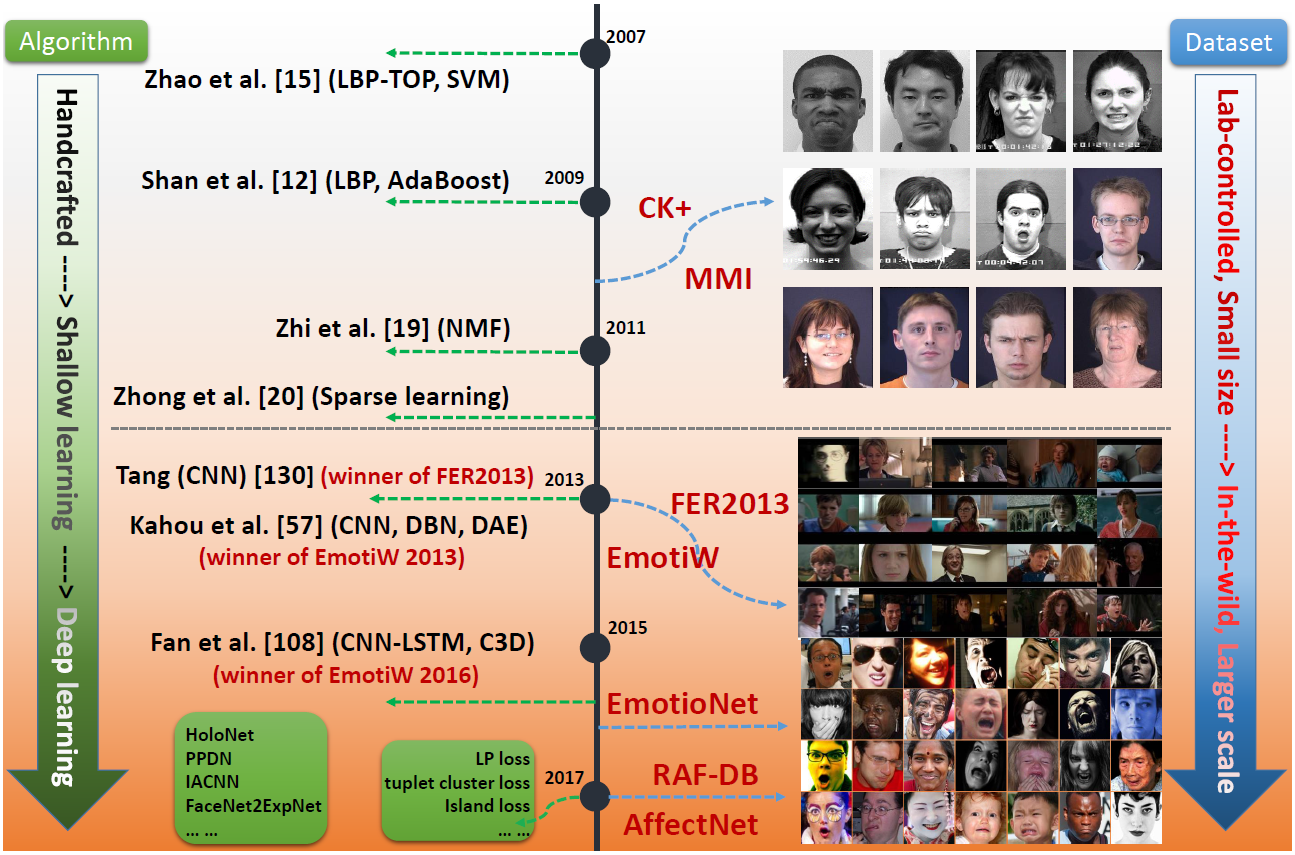 图X 人脸表情识别在数据集及方法上的演变 在这篇论文中,我们介绍一些用于解决以上问题的最新的深度FER的方法。首先,第2章介绍常用的人脸表情数据集,第3章介绍深度EFR系统中最主要的有三个步骤。……
图X 人脸表情识别在数据集及方法上的演变 在这篇论文中,我们介绍一些用于解决以上问题的最新的深度FER的方法。首先,第2章介绍常用的人脸表情数据集,第3章介绍深度EFR系统中最主要的有三个步骤。……
2 人脸表情数据集
拥有尽可能多的复杂环境的带标签的训练数据庥对于深度人脸表情识别系统的设计量至关重要的。在这一章,我们主要讨论那些包含基本表情,并广泛应用于深度学习算法评估的公共数据集。表X提供了这些数据集的概览。包含人的数量,图片或视频用例的数量,数据集收集的环境,表情的分布和其它信息。 表X 人脸表情数据集概览 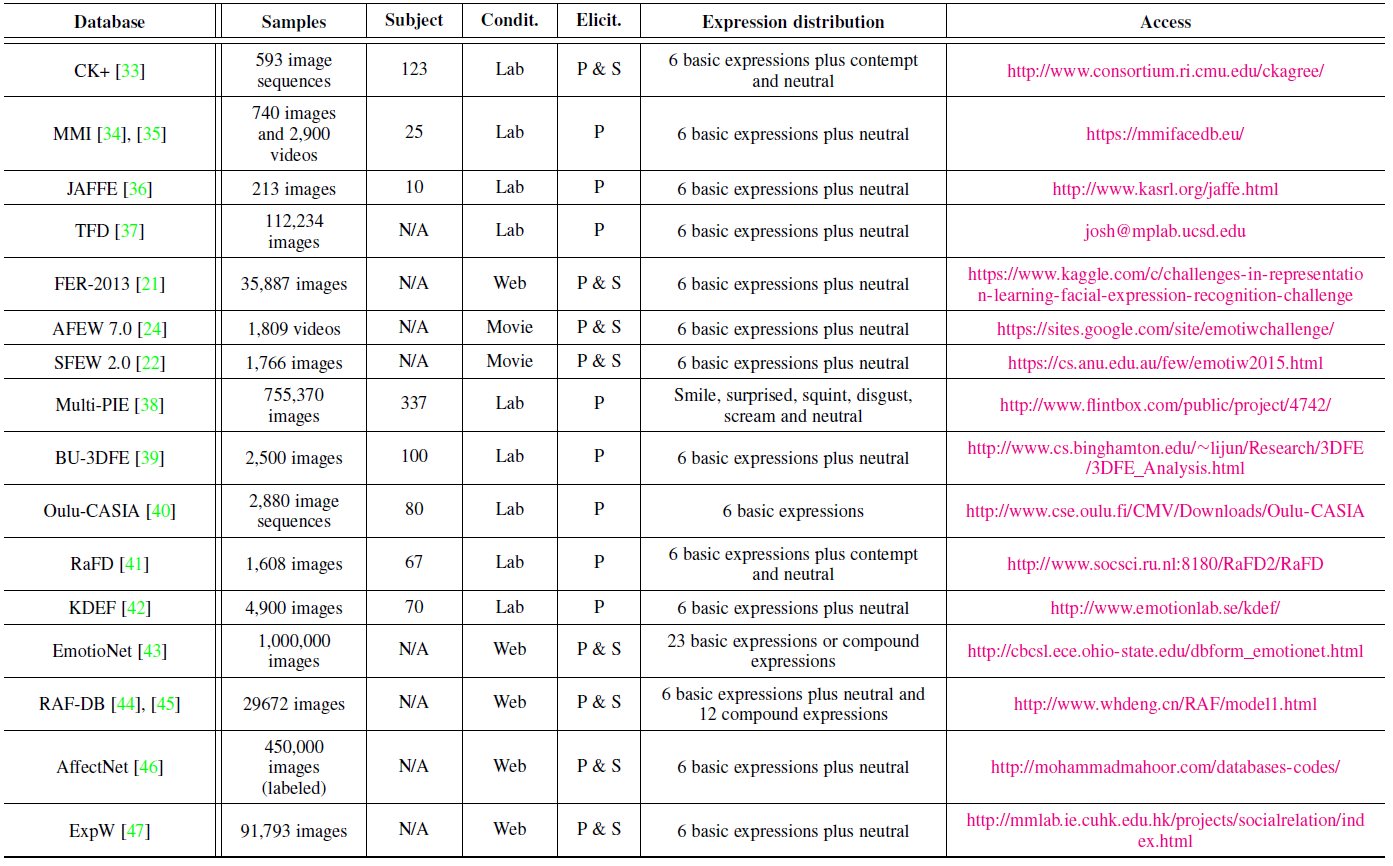 CK+:CK+数据集是评估FER系统中应用最广泛的采集于实验室的数据集。CK+数据集包含来自123个人的593个视频序列,这些序列从10帧到60帧数量不等,并且展示出表情从中性到峰值的变化。这些视频序列都标有基于FACS的七个基本的表情标签(愤怒,蔑视,厌恶,害怕,高兴,悲伤,惊讶)。因为CK+并不提供特定的训练集,验证集和测试集,所有算法在这个数据集的评估方式存在差异,基于静态图片的最觉见的数据选取方法是提取每一个视频序列的第一帧,带有峰值信息的三帧及最后一帧。然后,将这些受试者被分成n组来进行n重交叉验证实验,通常选取的n值为5, 8, 10。 JAFFE:日本女性表情数集(JAFFE)是一个在实验室采集的图像数据集,其中包含来自10名日本女性的213张姿态表情。每一个人都有3-4张基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶),有一张中性的表情。由于该数据集拥有较少的图片,导致它具有一定的挑战性。 FER2013:FER2013数据集首次在ICML2013特征学习挑战赛中提出的。FER2013是使用谷歌图片搜索引擎自动收集的大规模,不受约束的数据集。所有的图片大小被调整到$48\times48$的。FER2013中包含28709张训练数据集,3589张验证数据集和3589张测试数据集,每张图片标注有七种标签(愤怒,厌恶,害怕,高兴,悲伤,惊讶和中性)之一。 AFEW:AFEW(Acted Facial Expression in the Wild)数据集自2013年起开始作为每年的EmotiW(Emotion Recognition in the Wild Challenge)的评测平台。AFEW包含来自不同的电影带有连续表情的电影片段,其中涉及姿态,遮挡和光照等复杂环境。每个样例标记有七个表情:愤怒,厌恶,恐惧,高兴,悲伤,惊讶和中性。表情的标签在持续更新,并有现实中的真人秀节目的数据不断增加进来。 EmotiW2017的AFEW 7.0数据集按照来自电影或真人秀的受试者将数据集分成三部分:训练集(773个),验证集(383个),测试集(653个)。 SFEW:SFEW(The Static Facial Expressions in the Wild)是基于脸部关键点计算关键帧从AFEW数据集中选取静态帧组成的。最常用的版本是SFEW2.0,其是EmotiW2015中SReco子挑战的基准数据集。SFEW2.0被分成三个数据集:训练数据集(958个),验证数据集(436个)和测试数据集(372个)。每张图片都被标记为七种表情种类(愤怒,厌恶,害怕,中性,高兴,悲伤和惊讶)的一种。 BU-3DFE:BU-3DFE(Binghamton University 3D Facial Expression)包含来自100个人的606个人脸表情序列。对于每张图片,都显式的标出6种基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶)的强度。和Multi-PIE相似,这个数据集通常被用于3D人脸表情分析。 Oulu-CASIA:Oulu-CASIA数据集包含来自80个个体共2880个视频序列,都标有六种基本表情标签:愤怒,厌恶,害怕,高兴,悲伤和惊讶等。环境为近红外光,可见光,三种不同的光照条件。同CK+数据集类似,它的第一帧是中性表情,最后一帧有峰值表情。特别是来自480个视频的最后三帧峰值表情和第一帧用来做10重交叉验证实验。 EmotionNet:EmotionNet是一个大型的数据集,它拥有100万张收自网络的人脸表情图片。其中的95万张图片用AU检测模型(action unit)来自动标注,剩下的25万张图片则是用11AUs去手动标注。在EmotinNet挑战赛上,提供了带有6种基本表情和10种综合表情标签的2478张图片。 RAF-DB:RAF-DB(Real-world Affective Face Database)是包含下载自互联网的29672张表情图片的真实世界的数据集。借助手动标注和可靠的估算,每个样例标有7个基本表情和11个综合表情标签。基本表情数据集中15339张图片被分成两组(12271个训练样例和3068个测试用例)用来评估算法性能。 AffectNet:AffectNet数据集包含来自网络的100多万张图片,每张图片使用不同的搜索引擎用与表情相关的关键字查询所获得。其中的45张图片已经被手式标注了8个基本表情标签。 ExpW:ExpW(Expression in-the-Wild Database)包含91793张使用google图片搜索引擎下载的人脸图片,每一张人脸的图片都被手动标注为7种基本表情的一种,无人脸的图片将在标注过程中移除掉。
CK+:CK+数据集是评估FER系统中应用最广泛的采集于实验室的数据集。CK+数据集包含来自123个人的593个视频序列,这些序列从10帧到60帧数量不等,并且展示出表情从中性到峰值的变化。这些视频序列都标有基于FACS的七个基本的表情标签(愤怒,蔑视,厌恶,害怕,高兴,悲伤,惊讶)。因为CK+并不提供特定的训练集,验证集和测试集,所有算法在这个数据集的评估方式存在差异,基于静态图片的最觉见的数据选取方法是提取每一个视频序列的第一帧,带有峰值信息的三帧及最后一帧。然后,将这些受试者被分成n组来进行n重交叉验证实验,通常选取的n值为5, 8, 10。 JAFFE:日本女性表情数集(JAFFE)是一个在实验室采集的图像数据集,其中包含来自10名日本女性的213张姿态表情。每一个人都有3-4张基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶),有一张中性的表情。由于该数据集拥有较少的图片,导致它具有一定的挑战性。 FER2013:FER2013数据集首次在ICML2013特征学习挑战赛中提出的。FER2013是使用谷歌图片搜索引擎自动收集的大规模,不受约束的数据集。所有的图片大小被调整到$48\times48$的。FER2013中包含28709张训练数据集,3589张验证数据集和3589张测试数据集,每张图片标注有七种标签(愤怒,厌恶,害怕,高兴,悲伤,惊讶和中性)之一。 AFEW:AFEW(Acted Facial Expression in the Wild)数据集自2013年起开始作为每年的EmotiW(Emotion Recognition in the Wild Challenge)的评测平台。AFEW包含来自不同的电影带有连续表情的电影片段,其中涉及姿态,遮挡和光照等复杂环境。每个样例标记有七个表情:愤怒,厌恶,恐惧,高兴,悲伤,惊讶和中性。表情的标签在持续更新,并有现实中的真人秀节目的数据不断增加进来。 EmotiW2017的AFEW 7.0数据集按照来自电影或真人秀的受试者将数据集分成三部分:训练集(773个),验证集(383个),测试集(653个)。 SFEW:SFEW(The Static Facial Expressions in the Wild)是基于脸部关键点计算关键帧从AFEW数据集中选取静态帧组成的。最常用的版本是SFEW2.0,其是EmotiW2015中SReco子挑战的基准数据集。SFEW2.0被分成三个数据集:训练数据集(958个),验证数据集(436个)和测试数据集(372个)。每张图片都被标记为七种表情种类(愤怒,厌恶,害怕,中性,高兴,悲伤和惊讶)的一种。 BU-3DFE:BU-3DFE(Binghamton University 3D Facial Expression)包含来自100个人的606个人脸表情序列。对于每张图片,都显式的标出6种基本表情(愤怒,厌恶,害怕,高兴,悲伤和惊讶)的强度。和Multi-PIE相似,这个数据集通常被用于3D人脸表情分析。 Oulu-CASIA:Oulu-CASIA数据集包含来自80个个体共2880个视频序列,都标有六种基本表情标签:愤怒,厌恶,害怕,高兴,悲伤和惊讶等。环境为近红外光,可见光,三种不同的光照条件。同CK+数据集类似,它的第一帧是中性表情,最后一帧有峰值表情。特别是来自480个视频的最后三帧峰值表情和第一帧用来做10重交叉验证实验。 EmotionNet:EmotionNet是一个大型的数据集,它拥有100万张收自网络的人脸表情图片。其中的95万张图片用AU检测模型(action unit)来自动标注,剩下的25万张图片则是用11AUs去手动标注。在EmotinNet挑战赛上,提供了带有6种基本表情和10种综合表情标签的2478张图片。 RAF-DB:RAF-DB(Real-world Affective Face Database)是包含下载自互联网的29672张表情图片的真实世界的数据集。借助手动标注和可靠的估算,每个样例标有7个基本表情和11个综合表情标签。基本表情数据集中15339张图片被分成两组(12271个训练样例和3068个测试用例)用来评估算法性能。 AffectNet:AffectNet数据集包含来自网络的100多万张图片,每张图片使用不同的搜索引擎用与表情相关的关键字查询所获得。其中的45张图片已经被手式标注了8个基本表情标签。 ExpW:ExpW(Expression in-the-Wild Database)包含91793张使用google图片搜索引擎下载的人脸图片,每一张人脸的图片都被手动标注为7种基本表情的一种,无人脸的图片将在标注过程中移除掉。
3 深度人脸表情识别
这一章,我们将介绍了深度FER中最主要的三个步骤,预处理,深度特征提取和深度特征分类。我们简短的总结了每个步骤广泛使用的算法。
3.1 预处理
一些变量像不同的背景,光照和姿态等都与人脸表情不相关,但是在无约束的场景是普通存在的。因此,在训练神经网络去学习有用的特征之前,需要用预处理来对齐人脸并规范人脸所传达出的视觉语义信息。
3.1.1 人脸对齐
人脸对齐在很多与人脸相关的识别的任务中是一个预处理的步骤。我们列出了一些广泛应用深度FER并公开算法实现的算法。对于训练数据,首先第一步是检测人脸,然后去除人脸和不相关的区域。Viola-Jones(V&J)人脸检测器是一个经典的并广泛应用人脸检测的检测器,它具有很强鲁棒性,并且计算简单。 表X 在深度FER中广泛应用的人脸对齐检测器的总结 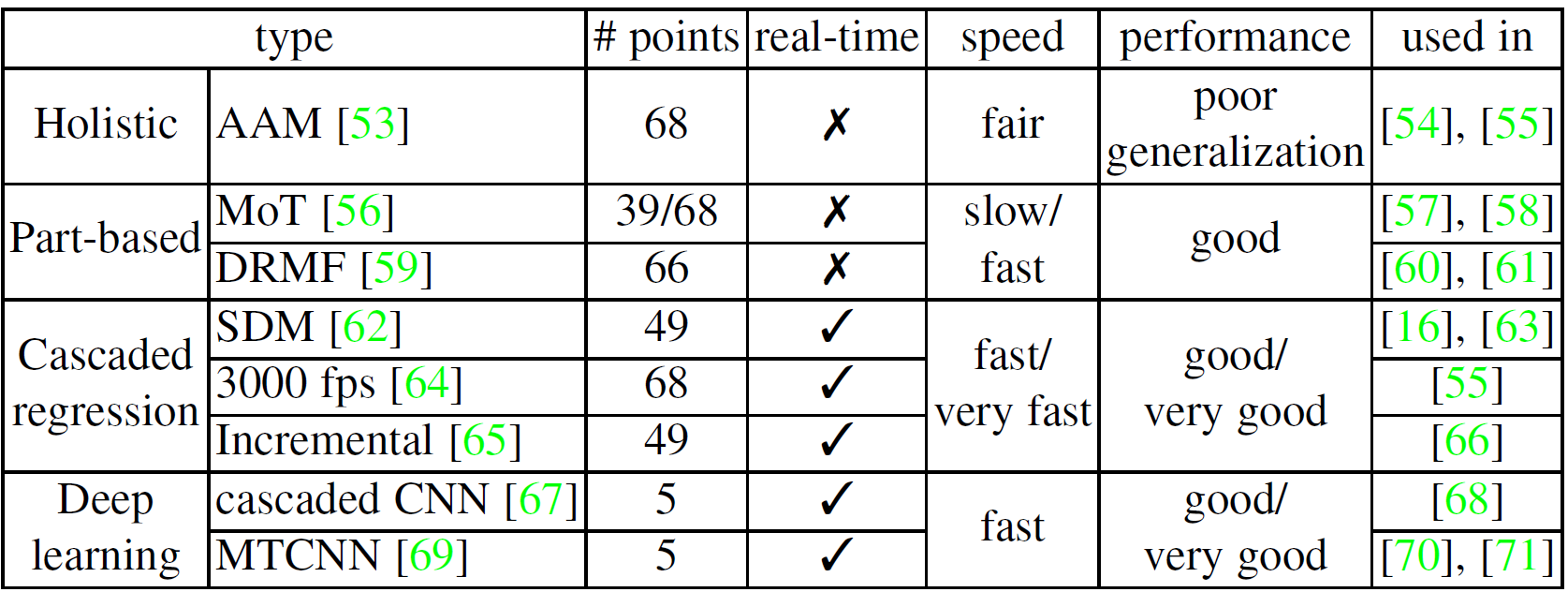 尽管人脸检测是特征学习前唯一的必不可少的过程,在检测后的人脸使用人脸对齐能进一步提高FER的性能。这一步是至关重要的,因为它能减小人脸规模和平面内旋转的变化。表X研究了广泛应用在深度FER中的人脸关键点检测算法并比较他们的执行效率及性能。主动外观模型(Active Appearance Model)是一个典型的生成式模型,优化全局的人脸外观和形状模型的参数。在判别式模型中,MoT(mixtures of trees)和DRMF(Disctiminative response map fitting)通过关键点周围的局部外观信息来表示人脸。另处,还有大量的差别式模型直接使用级联回归函数将图像外观特征映射到关键点位置,并显示更好的结果。比如在IntraFace中实现的SDM(supervised descent method),3000 fps和增量人脸对齐等等。最近,深度网络也广泛应用于人脸对齐。级联CNN是第一个用级联的方式来预测人脸关键点的深度算法。基于此,TCDCN(Tasks-Constrained Deep Convolutional Network)和多任务CNN(MTCNN)进一步利用多任务学习来提升性能。一般情况下,级联回归由于其高速和高精确度已经成为最流行和最新的算法。
尽管人脸检测是特征学习前唯一的必不可少的过程,在检测后的人脸使用人脸对齐能进一步提高FER的性能。这一步是至关重要的,因为它能减小人脸规模和平面内旋转的变化。表X研究了广泛应用在深度FER中的人脸关键点检测算法并比较他们的执行效率及性能。主动外观模型(Active Appearance Model)是一个典型的生成式模型,优化全局的人脸外观和形状模型的参数。在判别式模型中,MoT(mixtures of trees)和DRMF(Disctiminative response map fitting)通过关键点周围的局部外观信息来表示人脸。另处,还有大量的差别式模型直接使用级联回归函数将图像外观特征映射到关键点位置,并显示更好的结果。比如在IntraFace中实现的SDM(supervised descent method),3000 fps和增量人脸对齐等等。最近,深度网络也广泛应用于人脸对齐。级联CNN是第一个用级联的方式来预测人脸关键点的深度算法。基于此,TCDCN(Tasks-Constrained Deep Convolutional Network)和多任务CNN(MTCNN)进一步利用多任务学习来提升性能。一般情况下,级联回归由于其高速和高精确度已经成为最流行和最新的算法。
3.1.2 数据增强
深度卷积神经网络要求足够多的数据来确保模型在指定的识别任务下的泛化能力。然而大部分公开的人脸数据集并没有充分的人脸数据用于训练,因此,数据增强是深度FER中至关重要的一步。数据增增技术可分为两类:线下数据增强和在线数据增强。 通常情况下,线上数据增强被加入深度学习工具箱来防止过拟合。在训练过程中,输入的图片从图像的四角和中心随机裁剪,然后水平翻转,就能使得训练的数据集是原始的十倍。除了基础的线上数据增强,各种各样的离线数据增强被用来进一步扩充数据。最常用的操作包括:旋转,平移,尺寸变换,噪声,反转,畸变等。比如,常见的噪声模型像椒盐噪声,高斯噪声等被用于扩大数据量。多种操作相结合可以生成更多看不到的训练数据,使网络模型的鲁棒性更强。
3.1.3 人脸归一化
人脸图片中光照和头部姿态的变化对FER的性能有很大的影响,因此,我介绍了两种典型的人脸归一化方法来减少这些变化带来的影响:光照归一化和姿态归一化。 光照归一化:光照在不同的图片中都存在差异,即使是同一个人的相同表情也存在不同的光照,尤其在非限制的环境下,它会对结果产生很大影响。在[60]中,总结了几个常用的光照归一化方法:基于各向同性扩散归一化(isotropic diffusion-based normalization)、基于离散余弦变换归一化(DCT-based normalization)和高斯差分(DoG)。在[86]中使用了同态滤波归一化的方法,其相比其它方法,产生更加一致的结果。另外,有相关研究显示,将光照归一化与直方图均衡化相结合在人脸表情识别的性能比只使用光照归一化的性能要好。许多对深度FER的研究都在预处理阶段采用直方均衡图来增加图像整体的对比度。当图像的前景与背景的高度较接近时,这种方法是比较有效的。 姿态归一化:考虑到姿态变化在非受限的环境下是另一个常见的问题。一些研究采用姿态归一化技术来生成正面人脸图。其中Hassner提出的方法是最常用的,在对人脸的关键点进行定位后,对所有的人脸生成一个3D纹理参考模型估计可视人脸部分,然后将输入的人脸投影到参考的坐标系上,合成的人脸的正面图。最近,也提出了一些基于GAN的生成正面人脸的深度网络模型(FF-GAN,TP-GAN和DR-GAN)。
3.2 特征学习深度网络
深度学习最近是一个很火热的研究话题,在很多应用上都取得最新的性能表现。深度学习尝试使用多个非线性的转换和表示结构来捕获更高层次的特征抽象。在这一章,我们简短地介绍了应用于FER的深度学习技术。这些深度神经网络的结构如图X所示。 图X 深度表情识别系统的一般步骤 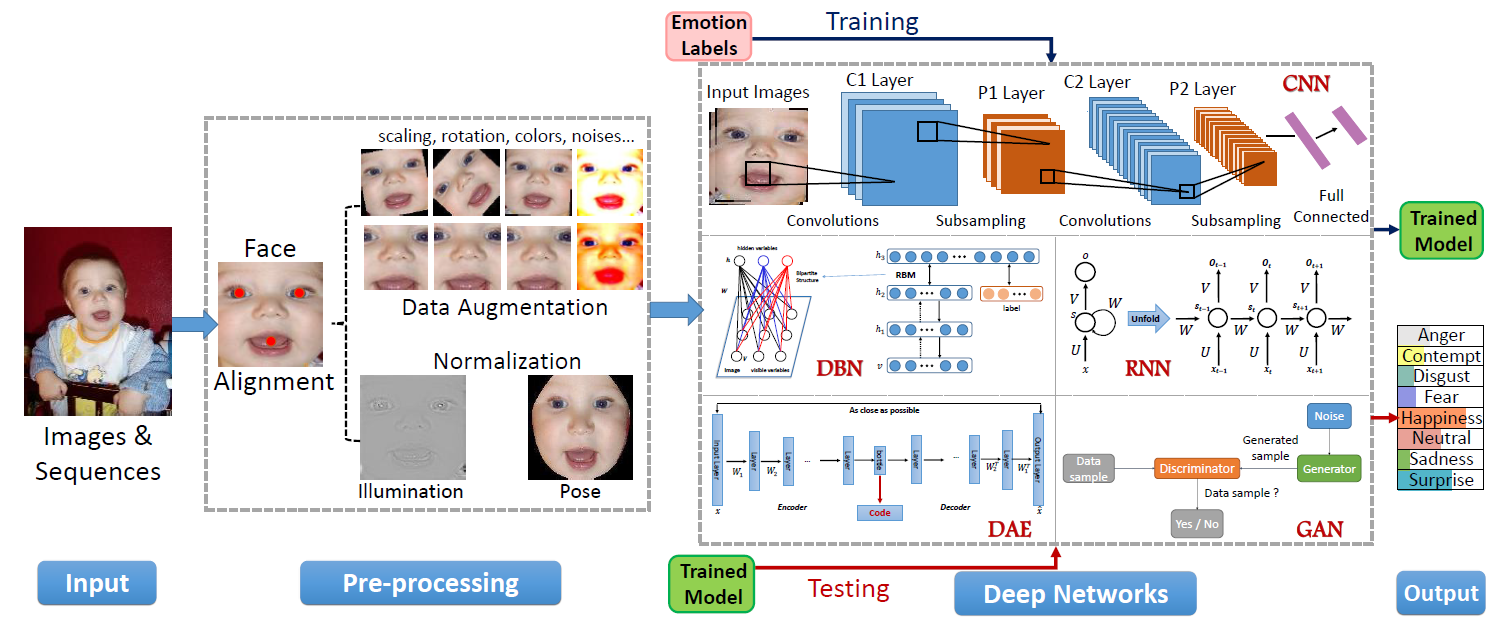 CNN在计算机视觉中广泛应用,一个CNN结构通常包含卷积层、池化层和全连接层等。在表X中我们列出了一些著名的CNN模型的构成和特征。除了这些神经网络,基于区域的CNN(R-CNN)也被用于FER中的特征学习,Faster R-CNN 通过生成高质量候选区域,识别面部表情。Ji et al提出的3D CNN通过3D卷积来对捕获多个相邻帧之间的动作信息来对动作进行识别。深度信念网络(DBN)是由Hinton提出的,学习提取训练数据的深度层次表示。DBN中,较高层的单元被训练去学习相邻低层的单元间的条件依赖,除了最高的两层,其余都没能直接连接。DBN的训练包含两个阶段:预训练和微调。首先用逐层贪婪训练方法初始化深度网络,可以在不需要大量标注数据的情况下防止局部最优解。然后,用有监督的梯度下降对网络的参数和输出进行微调。深度自编码器(Deep autoencoder)首次在[118]中提出来学习特征降维的有效编码,与之前的方法不同,DAE通过最小化重建误差来优化输入的重建。目前存在很多种DAE:降噪自编码器,可从部分损坏的数据中恢复原始未损坏数据;稀疏自编码网络,增强学习得到的特征表示的稀疏性;压缩式自编码器,增加活动相关正则项以提取局部不变特征;卷积自编码器,使用卷积层代替 DAE 中的隐藏层。循环神经网络(RNN)是联结主义的模型,能捕捉时间信息,对于任意长度的序列数据的预测是更合适的。时间的反向传播(BPTT)被用来训练RNN。由Hochreiter和Schmidhuber提出的LSTM是传统的RNN的一种特殊的形式被 用来解决常常出现在训练RNNs中的梯度消失和梯度爆炸的问题。LSTM能学习序列中的长时依赖,被广泛用于基于视频的表情识别的任务。
CNN在计算机视觉中广泛应用,一个CNN结构通常包含卷积层、池化层和全连接层等。在表X中我们列出了一些著名的CNN模型的构成和特征。除了这些神经网络,基于区域的CNN(R-CNN)也被用于FER中的特征学习,Faster R-CNN 通过生成高质量候选区域,识别面部表情。Ji et al提出的3D CNN通过3D卷积来对捕获多个相邻帧之间的动作信息来对动作进行识别。深度信念网络(DBN)是由Hinton提出的,学习提取训练数据的深度层次表示。DBN中,较高层的单元被训练去学习相邻低层的单元间的条件依赖,除了最高的两层,其余都没能直接连接。DBN的训练包含两个阶段:预训练和微调。首先用逐层贪婪训练方法初始化深度网络,可以在不需要大量标注数据的情况下防止局部最优解。然后,用有监督的梯度下降对网络的参数和输出进行微调。深度自编码器(Deep autoencoder)首次在[118]中提出来学习特征降维的有效编码,与之前的方法不同,DAE通过最小化重建误差来优化输入的重建。目前存在很多种DAE:降噪自编码器,可从部分损坏的数据中恢复原始未损坏数据;稀疏自编码网络,增强学习得到的特征表示的稀疏性;压缩式自编码器,增加活动相关正则项以提取局部不变特征;卷积自编码器,使用卷积层代替 DAE 中的隐藏层。循环神经网络(RNN)是联结主义的模型,能捕捉时间信息,对于任意长度的序列数据的预测是更合适的。时间的反向传播(BPTT)被用来训练RNN。由Hochreiter和Schmidhuber提出的LSTM是传统的RNN的一种特殊的形式被 用来解决常常出现在训练RNNs中的梯度消失和梯度爆炸的问题。LSTM能学习序列中的长时依赖,被广泛用于基于视频的表情识别的任务。 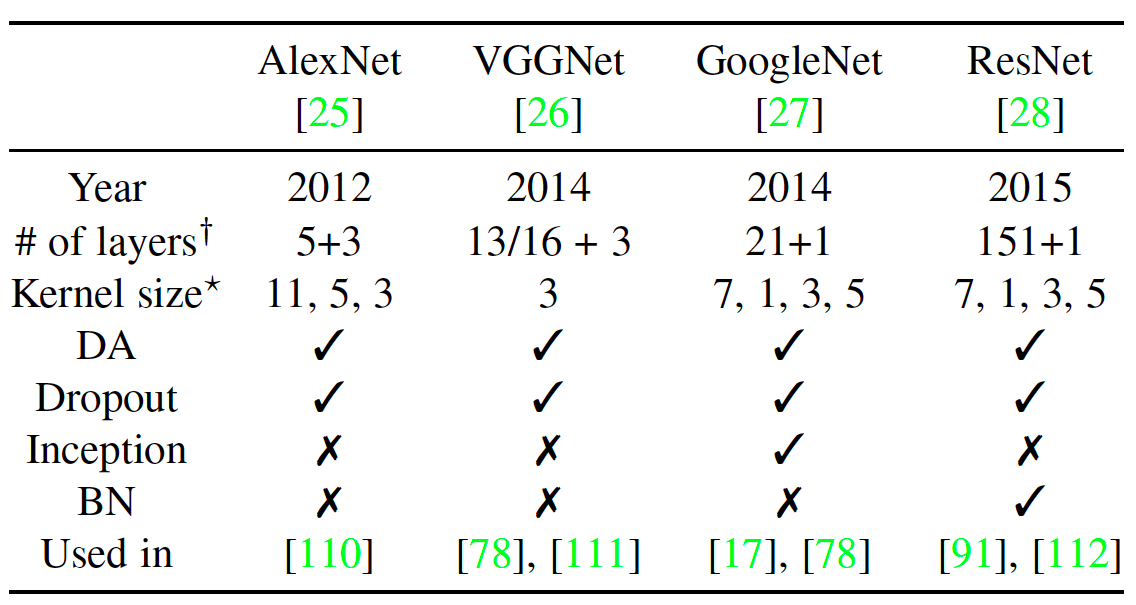
3.4 人脸表情分类
在学习到深度特征后,FER的最后一步是将给定的人脸进行表情分类。传统深度的特征提取和特征分类是相互独立的,而深度网络用一种端到端的形式来完成FER任务。特别是,在网络的最后能加入损失层来减少反向传播的误差,并且在网络的最后能够直接给出每个实例的预测概率。 在CNN中,softmax损失函数是最常使用的用来最小化预测类别与ground truth之间的交叉熵。论文[130]表明在端到端训练中使用支持向量机(SVM)分类比交叉熵的表现要好。 除了端到端的学习方式,另一种可选用的方式是采用深度神经网络(CNN)进行特征提取,然后再使用额外的分类器进行特征分类,比如支持向量机或随机森林等。
4 最新方法
在这一章,我们对用于FER的深度神经网络和用于表情相关问题而提出的训练策略进行研究。我们提供了现在的深度FER系统在常见的数据集上的性能表现。由于一些数据集并没有提供明确的提供训练,测试和验证集,与之相关的研究可能在不同的数据集,不同的实验条件下进行的,所以,我总结了识别实验有关数据集的选取与分组方法的信息。在静态图片上进行的表情分类研究有很多,因为不用考虑时间信息,并且数据处理方便,与训练和测试有关的数据集易获得。我们首先介绍了FER中预训练和微调的技巧,然后研究了这个领域的深度神经网络,对最常评估的数据集,在表X中显示在最新方法的性能表现。
4.1 预训练和微调
在相当小的数据集上直接训练,容易造成过拟合。为了解决这种总是,很多研究先在其它数据集上进行预训练,然后在训练好的网络进行微调(如AlexNet,VGG,GoogleNet等)。Kahou et al.实验证明使用额外的数据集能够帮助模型避免过拟合,并且能够提升FER的性能表现。 比起直接在预训练或微调的模型上对目标数据集进行特征提取,一个多阶段的微调策略(如图X所示)能获得更好的性能。第一阶段在预训练模型上使用 FER2013 进行微调,第二阶段利用目标数据库的训练数据进行微调,使模型更切合目标数据库。 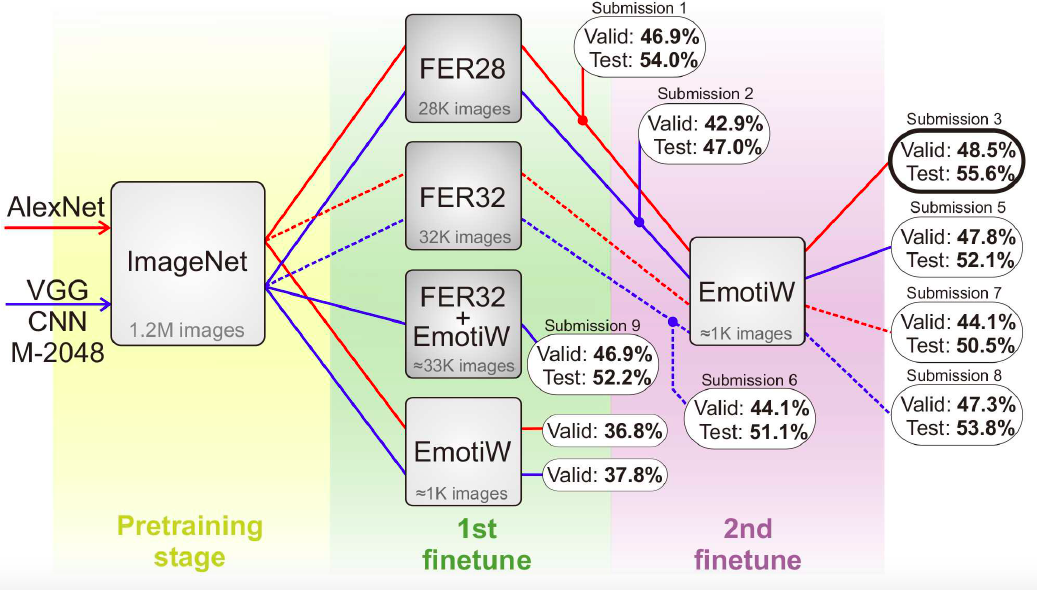 Ding 等人发现由于 FR 和 FER 数据库之间的差距,人脸主导的信息仍然遗留在微调的 FR 网络中,削弱了网络表示不同表情的能力。提出FaceNet2ExpNet的训练策略,如图X所示。微调的网络作为表情网络的初始值,仅能引导卷积层的学习,全连接层的训练则从头开始。
Ding 等人发现由于 FR 和 FER 数据库之间的差距,人脸主导的信息仍然遗留在微调的 FR 网络中,削弱了网络表示不同表情的能力。提出FaceNet2ExpNet的训练策略,如图X所示。微调的网络作为表情网络的初始值,仅能引导卷积层的学习,全连接层的训练则从头开始。
4.2 辅助网络块
基于CNN的基础架构,一些研究提出了一些设计好的辅助块或辅助层来增强学习到的与表情相关的特征的表达能力。 一个新颖的CNN网络HoloNet将CReLU与强有力的残差结构相结合,加深网络的深度。[165]设计出一个辅助块用于学习多尺度的特征来捕获人脸的变化。Hu 等人将 3 类有监督网络块嵌入 CNN 结构的实现浅层、中层和深层的监督。这些块根据原网络的层级特征表示能力设计。随后,每个块的类间评分在连接层进行累积,进行第二级的监督,如图所求。 图X [91]中三个不同的有监督网络块 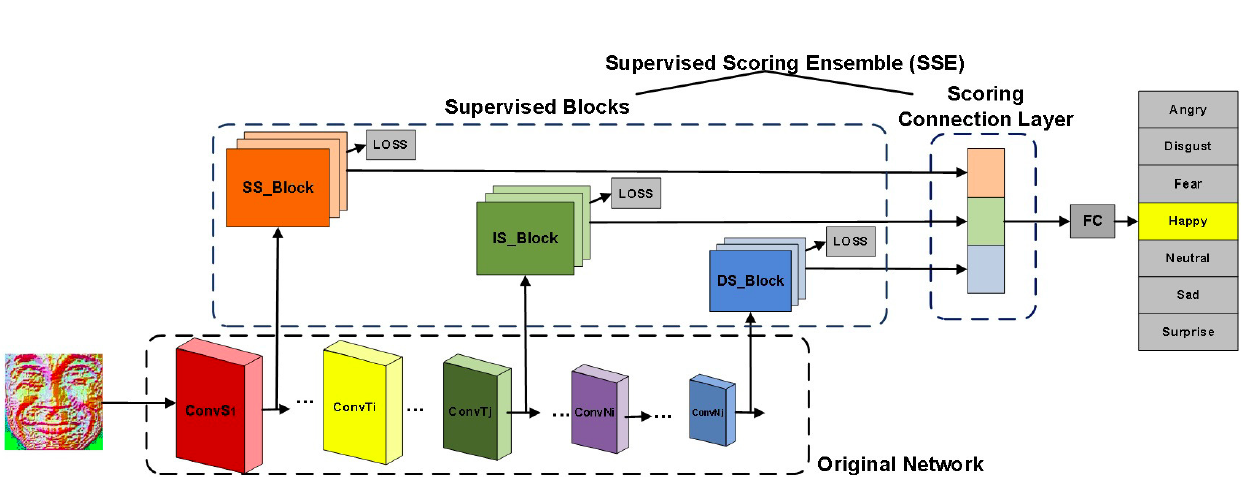 FSN(Feature Selection Network)是在AlexNet中加入了一个特征选择机制,它能自动过滤掉不相关特征,然后根据对人脸表情特征图的学习突出相关特征。Zeng et al.提出了IPA2LT(Inconsistent Pseudo Annotations to Latent Truth)结构,它通过将人类标注与机器标注最大似然化来发现不同数据集间机器的潜在真值。Cai 等人提出岛损失层。如图X所求。特征提取层计算的岛损失层和决策层计算的 softmax 损失结合起来监督 CNN 训练。Liu 等人提出(N+M)组聚类损失层。如图X所求在训练过程中,身份感知的难分样本挖掘和积极样本挖掘技巧用于降低同一表情类别下身份内部的变化所带来的影响。 图X [140]中的岛损失层
FSN(Feature Selection Network)是在AlexNet中加入了一个特征选择机制,它能自动过滤掉不相关特征,然后根据对人脸表情特征图的学习突出相关特征。Zeng et al.提出了IPA2LT(Inconsistent Pseudo Annotations to Latent Truth)结构,它通过将人类标注与机器标注最大似然化来发现不同数据集间机器的潜在真值。Cai 等人提出岛损失层。如图X所求。特征提取层计算的岛损失层和决策层计算的 softmax 损失结合起来监督 CNN 训练。Liu 等人提出(N+M)组聚类损失层。如图X所求在训练过程中,身份感知的难分样本挖掘和积极样本挖掘技巧用于降低同一表情类别下身份内部的变化所带来的影响。 图X [140]中的岛损失层 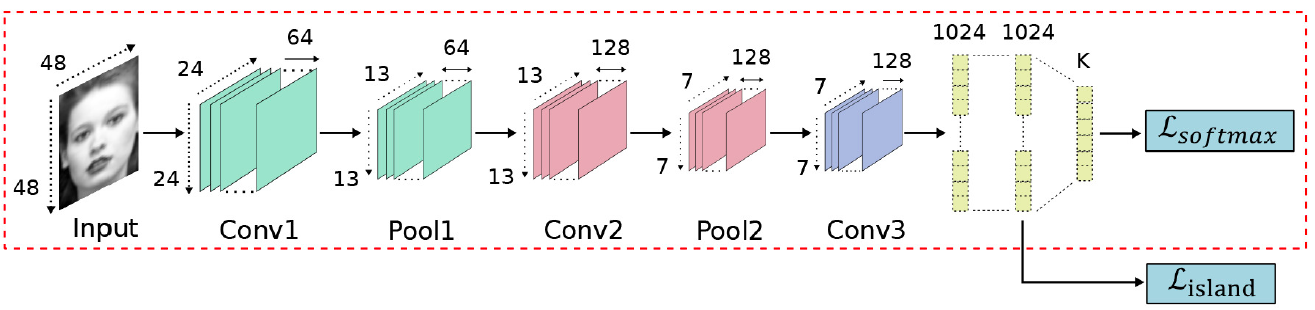 图X [77]组聚类损失层
图X [77]组聚类损失层 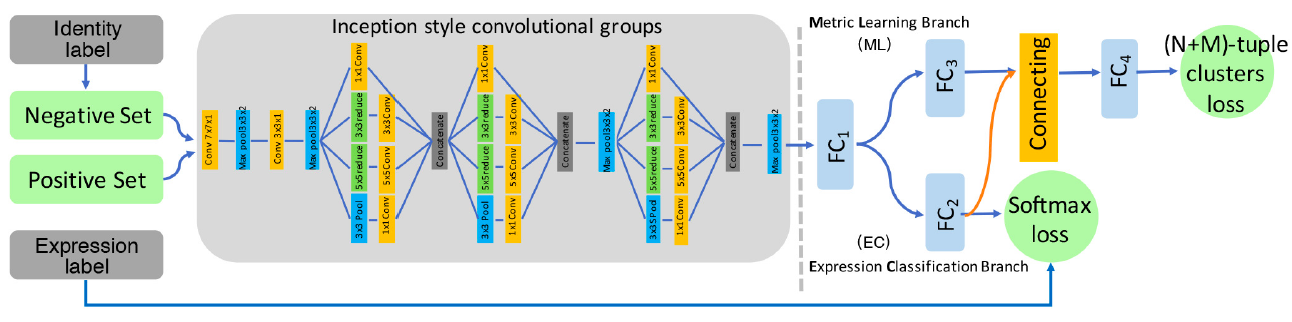
4.3 网络集成
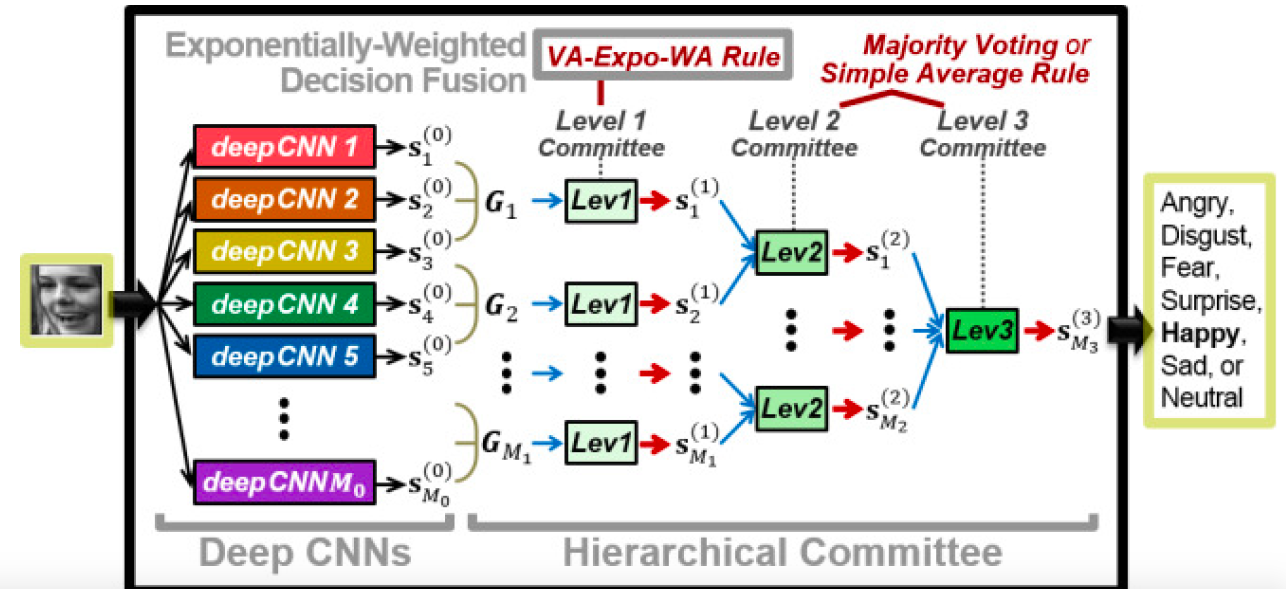
之前的研究表现多个网络的集成性能优于单个网络,在网络集成时,有两点需要注意:(1)多个网络的集成应确保功能多样且互补,而不是相同功能的堆砌。(2)采用合适的集成方法来有效地发挥各个网络的作用。 对于第一点,采用前面提到的预处理方法能产生不同的数据来训练多样的网络,通过改变卷积核的大小,层数,神经元的数目,采用随机初始化的方法来初始网络权重能加强网络的多样性。除此之外,不同的网络结构也能增加多样性。比如将用有监督学习的CNN与无监督学习的CAE进行网络集成。 对于第二点,网络可以在两个不同层面上进行组合:特征层和决策层。对于特征层,最常采取的方法是将不同网络学习得到的特征连接起来,组成一个新的特征矢量,来表示图像。如图X所求。在决策层,常用的三种方法是:多数投票、简单平均和加权平均。Kim 等人提出 3 级组合结构,在决策层融合,获取充分的决策多样性。如图X所求。 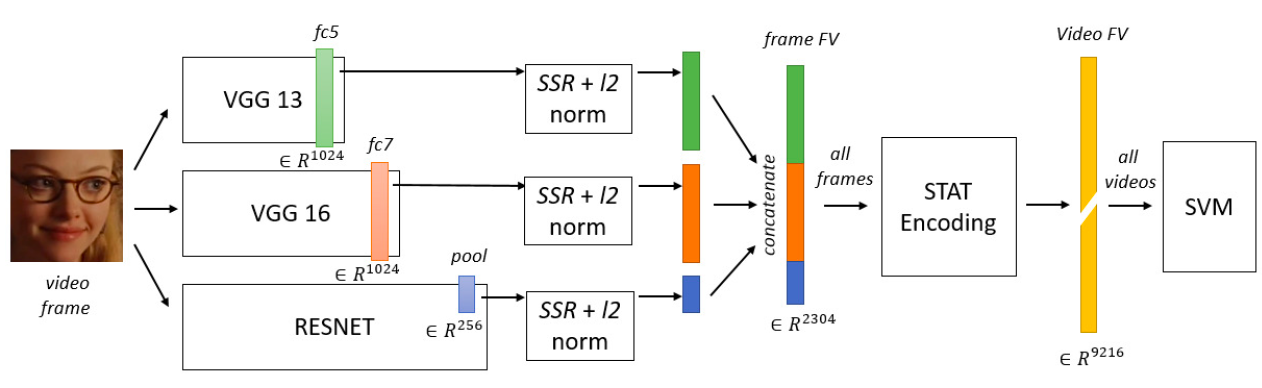
4.4 多任务网络
现在存在的很多网络都是单任务网络,学习到的特征由于没有考虑其它潜在因素与表情的联系,对表情敏感。然而真实世界中,FER和多个因素相关,像头的姿态,光照,个体差异等。为了解决这类问题,引入了多任务学习,将知识从其他相关任务中迁移出来,消除不利因素。 Reed等构造了建造了一个高阶玻尔兹曼机(disBM)学习与表情相关因素的流形坐标并提出了一种训练策略消除与表情相关的因素的影响。其它研究,将FER与其它任务同时进行,比如脸部关键点定位和脸部的Aus检测,它们的结合能有效提高FER的性能。除此之外,IACNN(Identity-aware CNN)采用两个完全相同的子CNN,一个使用对比损失来学习判别式表情特征,另一个用对比损失学习个体相关特征,在 Zhang 等人提出的 MSCNN 中,在训练时一对图像输入 MSCNN 网络。表情识别任务使用交叉熵损失,学习表情变化特征,面部识别人任务使用对比损失,减少同类表情特征之间的变化。如图X所示。 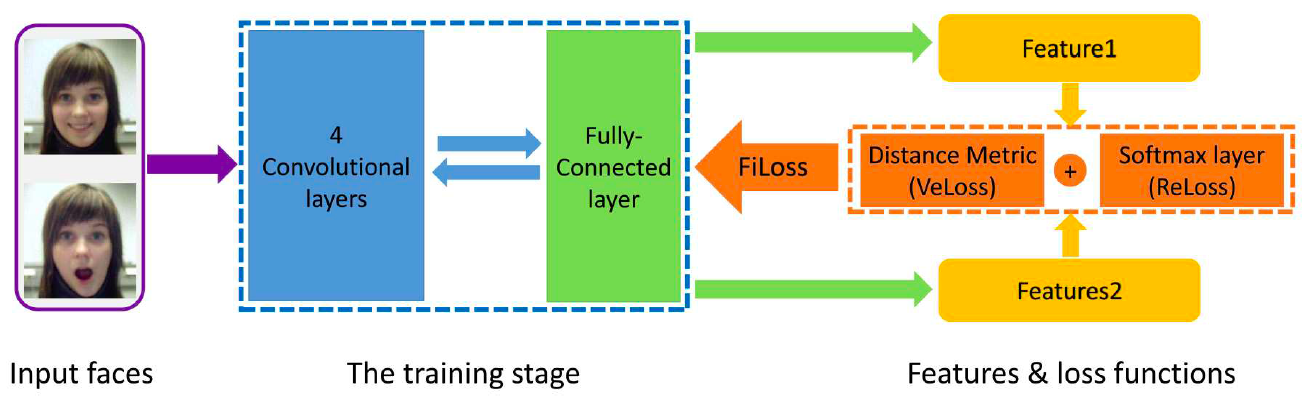
4.5 注意力网络
Attention机制在近几年来在图像,自然语言处理等领域中都取得了重要的突破,被证明有益于提高模型的性能。Attention机制本身也是符合人脑和人眼的感知机制,聚焦于局部信息的机制。 图X FERAtt的网络结构 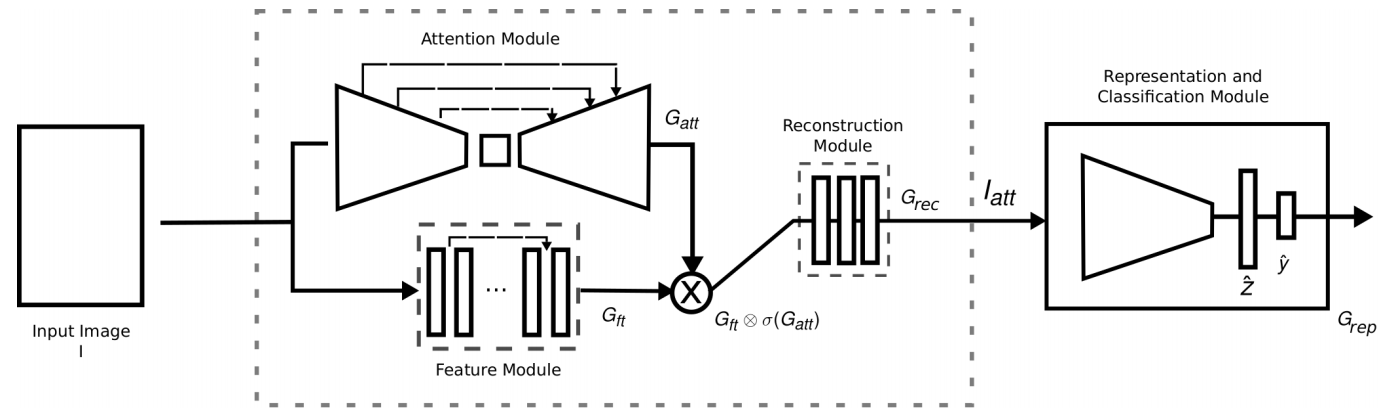 现在的很多研究,都是整张进行处理,引入噪声和不必要的计算。仿照人的注意力机制,Fernandez等人提出了一种注意力网络,如图X所求。共分为四个模块:注意力模块、特征提取模块、重建模块和分类再表示模块。并设计出高斯损失函数来优化特征表示。针对遮挡和姿态两大难题,Kai Wang等在FERplus,AffectNet、RAF-DB三个数据集的基础上筛选遮挡和姿态较大的图片创建了六个数据集Occlusion-FERPlus, Pose-FERPlus, Occlusion-AffectNet, Pose-AffectNet, Occlusion-RAF-DB, and Pose-RAF-DB。并设计出RAN(Region Attention Networks),如图X所求。并设计了RB-Loss,来提升区域在特征表示上的权重。该方法在多个数据集均有较大的性能提升。陆续将会有更多基于Attention机制的FER网络被提出,它在某些问题上的性能表现优于一般的网络结构。 图X RAN网络结构
现在的很多研究,都是整张进行处理,引入噪声和不必要的计算。仿照人的注意力机制,Fernandez等人提出了一种注意力网络,如图X所求。共分为四个模块:注意力模块、特征提取模块、重建模块和分类再表示模块。并设计出高斯损失函数来优化特征表示。针对遮挡和姿态两大难题,Kai Wang等在FERplus,AffectNet、RAF-DB三个数据集的基础上筛选遮挡和姿态较大的图片创建了六个数据集Occlusion-FERPlus, Pose-FERPlus, Occlusion-AffectNet, Pose-AffectNet, Occlusion-RAF-DB, and Pose-RAF-DB。并设计出RAN(Region Attention Networks),如图X所求。并设计了RB-Loss,来提升区域在特征表示上的权重。该方法在多个数据集均有较大的性能提升。陆续将会有更多基于Attention机制的FER网络被提出,它在某些问题上的性能表现优于一般的网络结构。 图X RAN网络结构 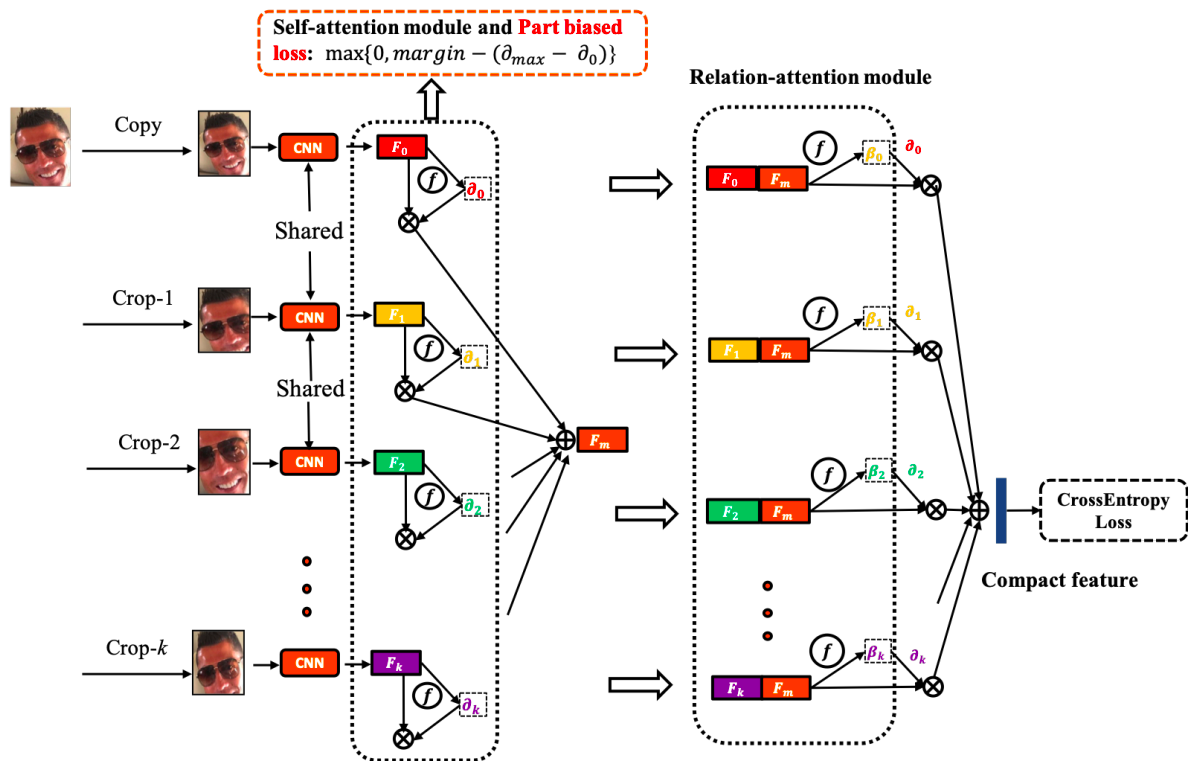 表X比较了不同类型的方法(预处理微调,辅助层,网络集成,多任务网络,注意力网络)对于数据大小的要求,在复杂环境(头的姿态,光照,遮挡和其它环境因素)的性能,计算效率,准确率,网络训练的难度。
表X比较了不同类型的方法(预处理微调,辅助层,网络集成,多任务网络,注意力网络)对于数据大小的要求,在复杂环境(头的姿态,光照,遮挡和其它环境因素)的性能,计算效率,准确率,网络训练的难度。 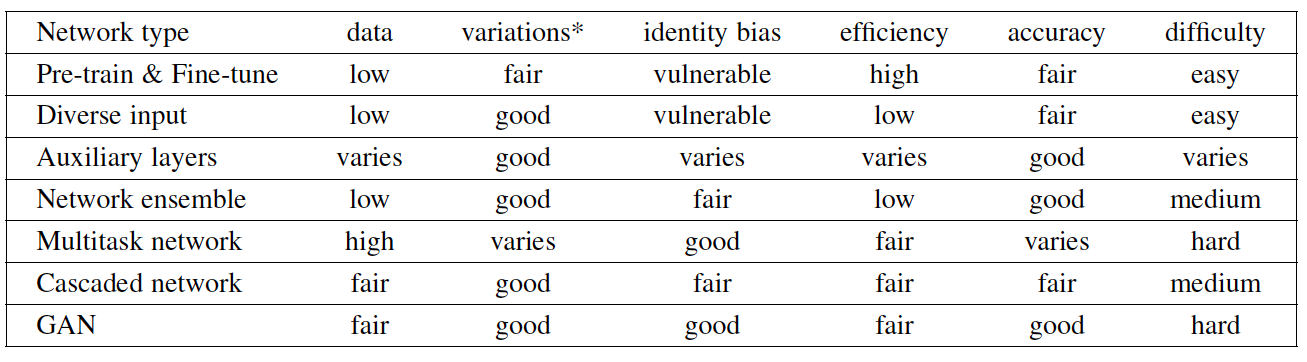
总结
由于 FER 研究将其主要关注点转移到具有挑战性的真实场景条件下,许多研究人员利用深度学习技术来解决这些困难,如光照变化、遮挡、非正面头部姿势、身份偏差和低强度表情识别。考虑到 FER 是一个数据驱动的任务,并且训练一个足够深的网络需要大量的训练数据,深度 FER 系统面临的主要挑战是在质量和数量方面都缺乏训练数据。由于不同年龄、文化和性别的人以不同的方式做出面部表情,因此理想的面部表情数据集应该包括丰富的具有精确面部属性标签的样本图像,不仅仅是表情,还有其他属性,例如年龄、性别、种族,这将有助于跨年龄、跨性别和跨文化的深度 FER 相关研究。另一方面,对大量复杂的自然场景图像进行精准标注是构建表情数据库一个明显的障碍。