FERAtt: Facial Expression Recognition with Attention Net阅读笔记
预览
这是一篇CVPRW2019的论文,作者将Attention机制引入到人脸表情识别中。提出Attention model,并写出了一个合成图片的生成器,模型对噪声有较强的鲁棒性,并在CK+,BU-3DFE数据集上有一定的性能提升。
原文地址和github源码地址
Problem
Recent developments for the facial expression recognition problem consider processing the entire image regardless of the face crop location within the image. Such developments bring in extraneous artifacts, including noise,which might be harmful for classification as well as incur in unnecessary additional computational cost. This is problematic as the minutiae that characterizes facial expressions can be affected by elements such as hair, jewelry, and other environmental objects not defining the actual face and as part of the image background.
作者认为现在存在的很多研究关注在整张人脸,带来不必要的计算,并引入了一些噪声可能对识别性能产生影响,引入的一些因素像头发,珠宝等并不能决定表情识别的结果,应该作为图片的背景。
Method
引入Attention机制,像人类的视觉感知一样,只关注目标区域的处理,与之无关的信息直接丢弃。如图所示。 

Network architecture
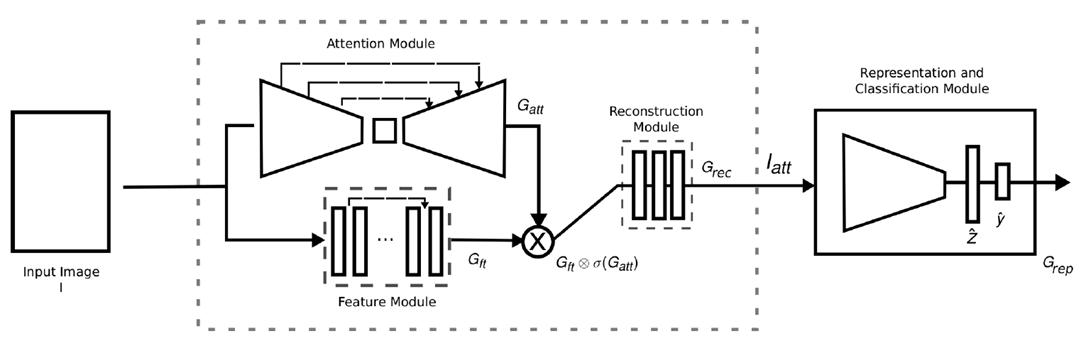 网络结构由4部分组成:注意力模块,特征提取模块,重建模块和分类表示模块。
网络结构由4部分组成:注意力模块,特征提取模块,重建模块和分类表示模块。
Attention Module
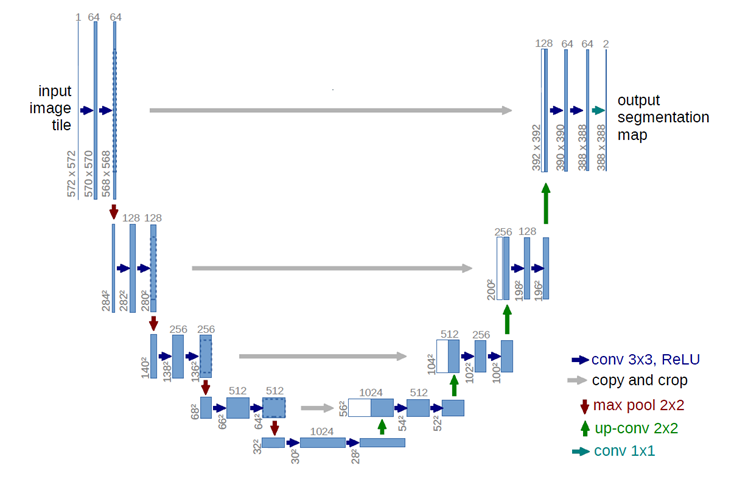 Attention模块将传统的人脸检测来用图像分割来代替。用了U-net来对图片进行分割,输出的是人脸的掩模。如图所示
Attention模块将传统的人脸检测来用图像分割来代替。用了U-net来对图片进行分割,输出的是人脸的掩模。如图所示 

Feature extration Module
Four ResBlocks were used to extract high-dimensional features for image attention and to maintain spatial information; no pooling or strided convolutional layers were used.
使用4个ResBlocks来提取高维度特征,保留空间信息。如图所示。 
Reconstruction Module
The reconstruction layer adjusts the attention map to create an enhanced input to the representation module. This module has two convolutional layers, a Relu layer, and an Average Pooling layer which, by design choice, resizes the input image of 128 × 128 to 32 × 32.
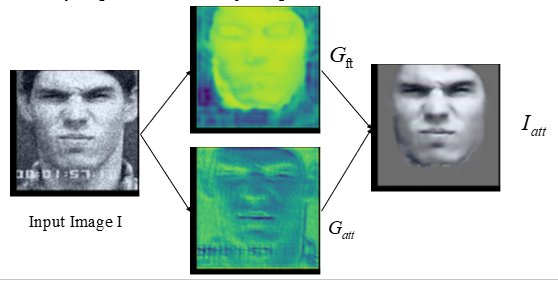
Representation and classification module
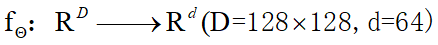 the network function, builds a representation for a sample image $x \\in R^D$ 主要是建立一个网络,对图片进行再表示,它的分类结果要与原图的分类结果足够接近。
the network function, builds a representation for a sample image $x \\in R^D$ 主要是建立一个网络,对图片进行再表示,它的分类结果要与原图的分类结果足够接近。 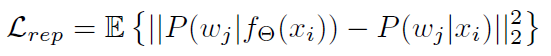 详细过程参照论文,比较复杂。
详细过程参照论文,比较复杂。
损失函数
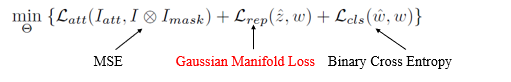
expriments
实验部分主要进行Rep模块的对照实验,数据集上的性能比较及算法对噪声的鲁棒性实验。
Datasets
Our image renderer R creates a synthetic larger dataset using real face datasets by making background changes and geometric transformations of face images.
将真实的人脸数据背景进行更换,然后再对人脸图片进行几何变换得到合成数据集。具体过程如图所示。  使用的数据集有CK+、BU-3DFE、COCO dataset.其中COCO dataset 用作背景图。最后合成的数据集部分如图所示。
使用的数据集有CK+、BU-3DFE、COCO dataset.其中COCO dataset 用作背景图。最后合成的数据集部分如图所示。 
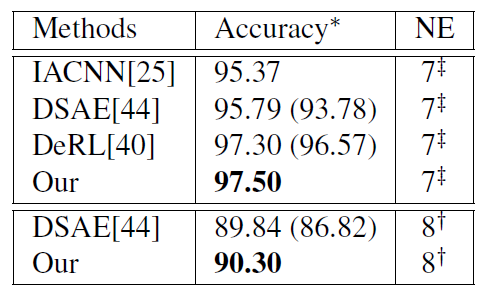
Expression recognition results
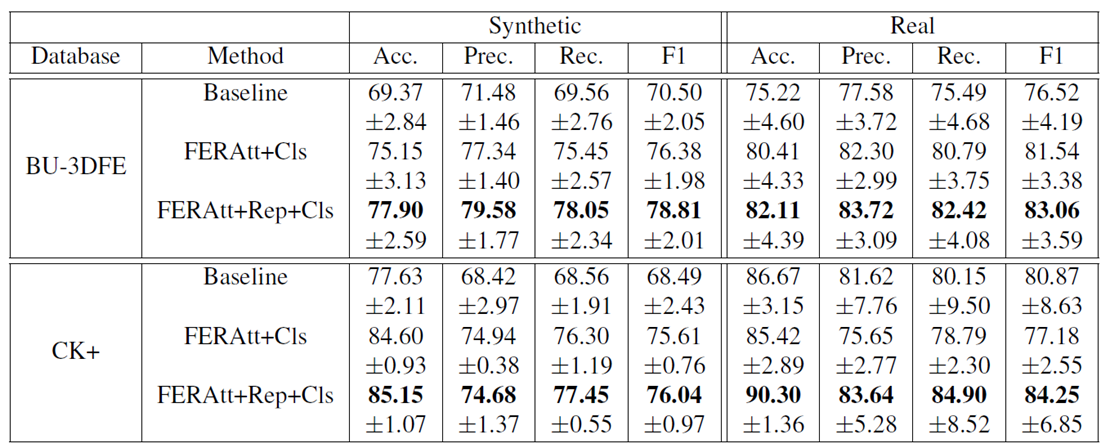 Baseline为PreActResNet18,将其与FERAtt+Cls 和FERAtt + Rep + Cls两种方法进行性能比较,发现再表示对性能的提升有明显的效果。
Baseline为PreActResNet18,将其与FERAtt+Cls 和FERAtt + Rep + Cls两种方法进行性能比较,发现再表示对性能的提升有明显的效果。 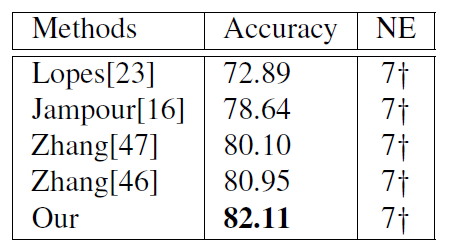
Rebustness to noise

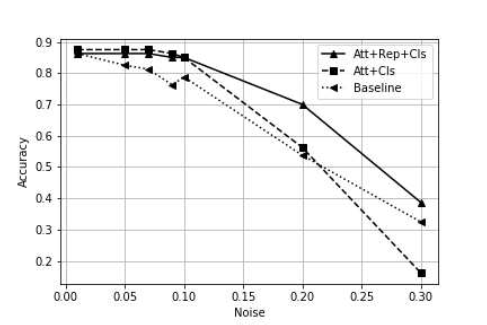
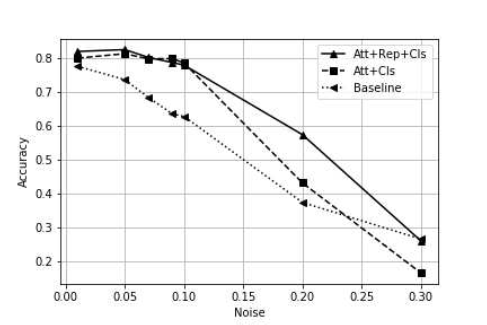 FERAtt + Rep + Cls算法对噪声的鲁棒性较好,在$\\sigma = 0 - 0.10$对于识别性能几乎无影响,继续增大$\\sigma$的值时,它的识别的精度也一直处于其它算法之上。
FERAtt + Rep + Cls算法对噪声的鲁棒性较好,在$\\sigma = 0 - 0.10$对于识别性能几乎无影响,继续增大$\\sigma$的值时,它的识别的精度也一直处于其它算法之上。
Contribution
- Attention model
- A generator of synthetic images
- Gaussian Manifold Loss