在训练过程中,我们常常会使用预训练模型,有时我们是在自己的模型中加入别人的某些模块,或者对别人的模型进行局部修改,这个时候再使用torch.load(model.state_dict()),就会出现类似这些的错误:RuntimeError: Error(s) in loading state_dict for Net:Missing key(s) in state_dict:xxx。出现这个错误就是某些参数缺失或者不匹配。
保持原来网络层的名称和结构不变
现有模型中引入的那部分网络结构的网络层的名称和结构保持不变,这时候加载参数的代码很简单。
1 2 3 4 5 6 7 8 9 10 11 12
# 加载引入的网络模型 model_path = "xxx" checkpoint = torch.load(os.path.join(model_path, map_location=torch.device('cpu')) pretrained_dict = checkpoint['net'] # 获取现有模型的参数字典 model_dict = model.state_dict() # 获取两个模型相同网络层的参数字典 state_dict = {k:v for k,v in pretrained_dict.items() if k in model_dict.keys()} # update必不可少,实现相同key的value同步 model_dict.update(state_dict) # 加载模型部分参数 model.load_state_dict(model_dict)
intgetProduct(int k){ int len = vec.size(), res = 1; for(int i = len - 1; i >= len - k; --i){ res = res * vec[i]; } return res; } };
/** * Your ProductOfNumbers object will be instantiated and called as such: * ProductOfNumbers* obj = new ProductOfNumbers(); * obj->add(num); * int param_2 = obj->getProduct(k); */
/** * Your ProductOfNumbers object will be instantiated and called as such: * ProductOfNumbers* obj = new ProductOfNumbers(); * obj->add(num); * int param_2 = obj->getProduct(k); */
在对h5文件写的过程中,首先遇到了错误OSError: Cannot write data (no appropriate function for conversion path),网上搜索之后,与之相关的问题很少,大部分提到的是字符串编码问题,参照资料1,对字符串的编码修改,但错误依旧。在这个地方卡了很长时间,一直检查数据类型哪里是不是有问题?最后尝试性,将最后创建数据集中的dtype去掉,即置为None。即将
files = os.listdir(anger_path) files.sort() for filename in files: I = skimage.io.imread(os.path.join(anger_path,filename)) image = cv2.imread(os.path.join(anger_path,filename)) res, flag = get_mask(image) data_x.append(I.tolist()) data_y.append(0)
if flag == True: res = res * 255 seg_image_data = res.tolist() data_z.append(seg_image_data) imageCount = imageCount + 1 print(imageCount)
files = os.listdir(anger_path) files.sort() for filename in files: I = skimage.io.imread(os.path.join(anger_path,filename)) image = cv2.imread(os.path.join(anger_path,filename)) res, flag = get_mask(image) if flag == True: data_x.append(I.tolist()) data_y.append(0) res = res * 255 seg_image_data = res.tolist() data_z.append(seg_image_data) imageCount = imageCount + 1 print(imageCount)
将别人模型替换成自己的模型,训练过程中出现错误param.grad.data.clamp_(-grad_clip, grad_clip) AttributeError: 'NoneType' object has no attribute 'data'
解决方法
上网查询这个问题,大部分回答都是模型中定义的某个层没有参与到前向传播,所以反向传播,计算loss时,grad is None。主要是要找到未参与计算的层,并注释掉。 这个问题困扰我很久,因为始终觉得没有多余的层。 下面的代码定义一个AttentionResNet模型。后来才发现罪魁祸首是self.encoder,这所以前面一直没有注意到它,是因为后面的层的定义用到self.encoder中的某个层或某几个层组合。
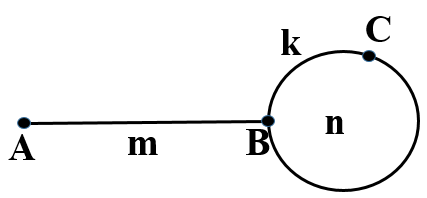
t := &S h := &S //令指针t和h均指向起始节点S。 repeat t := t->next h := h->next if h is not NULL //要注意这一判断一般不能省略 h := h->next until t = h or h = NULL if h != NULL //如果存在环的話 n := 0 repeat //求环的度 t := t->next n := n+1 until t = h t := &S //求环的一个起点 while t != h t := t->next h := h->next P := *t
How do you determine if your singly-linked list has a cycle? In 1980, Brent invented an algorithm that not only worked in linear time, but required less stepping than Floyd’s Tortoise and the Hare algorithm (however it is slightly more complex). Although stepping through a ‘regular’ linked list is computationally easy, these algorithms are also used for factorization and pseudorandom number generators, linked lists are implicit and finding the next member is computationally difficult.
Brent’s algorithm features a moving rabbit and a stationary, then teleporting, turtle. Both turtle and rabbit start at the top of the list. The rabbit takes one step per iteration. If it is then at the same position as the stationary turtle, there is obviously a loop. If it reaches the end of the list, there is no loop. Of course, this by itself will take infinite time if there is a loop. So every once in a while, we teleport the turtle to the rabbit’s position, and let the rabbit continue moving. We start out waiting just 2 steps before teleportation, and we double that each time we move the turtle.
Note that like Floyd’s Tortoise and Hare algorithm, this one runs in O(N). However you’re doing less stepping than with Floyd’s (in fact the upper bound for steps is the number you would do with Floyd’s algorithm). According to Brent’s research, his algorithm is 24-36% faster on average for implicit linked list algorithms.
All images in torchvision have to be represented as 3-dimensional tensors of the form [Channel, Height, Width]. I’m guessing your float tensor is a 2d tensor (height x width). For example, this works:
The error states that the DataLoader receives a PIL image. This is because there are no transforms made (transform=None) on the image. The getitem method of MyDataset passes an unprocessed PIL image to the DataLoader, whereas it should receive a tensor. You can add a transform that creates a tensor from the PIL image by adding transform:

 然后对图片同时进行随机旋转和翻转,代码如下
然后对图片同时进行随机旋转和翻转,代码如下
 50%可能性翻转后图片为
50%可能性翻转后图片为 
 随机裁剪,裁剪后大小为原来的[0.8,1],长宽比例为1:1,最后并将resize为(48, 48),图片为:
随机裁剪,裁剪后大小为原来的[0.8,1],长宽比例为1:1,最后并将resize为(48, 48),图片为: 

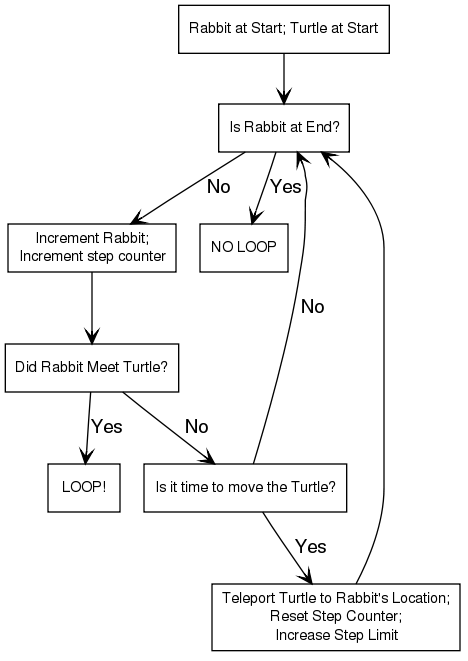 Brent’s algorithm features a moving rabbit and a stationary, then teleporting, turtle. Both turtle and rabbit start at the top of the list. The rabbit takes one step per iteration. If it is then at the same position as the stationary turtle, there is obviously a loop. If it reaches the end of the list, there is no loop. Of course, this by itself will take infinite time if there is a loop. So every once in a while, we teleport the turtle to the rabbit’s position, and let the rabbit continue moving. We start out waiting just 2 steps before teleportation, and we double that each time we move the turtle.
Brent’s algorithm features a moving rabbit and a stationary, then teleporting, turtle. Both turtle and rabbit start at the top of the list. The rabbit takes one step per iteration. If it is then at the same position as the stationary turtle, there is obviously a loop. If it reaches the end of the list, there is no loop. Of course, this by itself will take infinite time if there is a loop. So every once in a while, we teleport the turtle to the rabbit’s position, and let the rabbit continue moving. We start out waiting just 2 steps before teleportation, and we double that each time we move the turtle.