Facial Expression Recognition by De-expression Residue Learning阅读笔记
预览
这是一篇CVPR2018关于表情识别的论文,作者可谓是独辟蹊径,从“De-expression”这一角度进行表情识别的研究。作者通过一些事实和文献发现,人的表情可以分解为Neutral Compoent和Expressive Componet两部分。作者的想法是将人脸经过一个GAN网络得到一张与之对应的中性表情,然后对residue(残余特征)进行训练学习,进一步进行表情分类。
原文地址
原文地址 没有相应的源代码:sweat:
Challenge
现在的大部分研究关注的都是光照,姿态,遮挡等对表情识别的影响。作者关注的是个体差异像年龄,性别,种族背景等因素对表情识别的影响(the current main challenge comes from the large variations of individuals in attributes such as: age, gender, ethnic background and personality.)
Inspriation
- people are capable of recognizing facial expressions by comparing a subject’s expression with a reference expression (i.e., neutral expression) of the same subject[1].
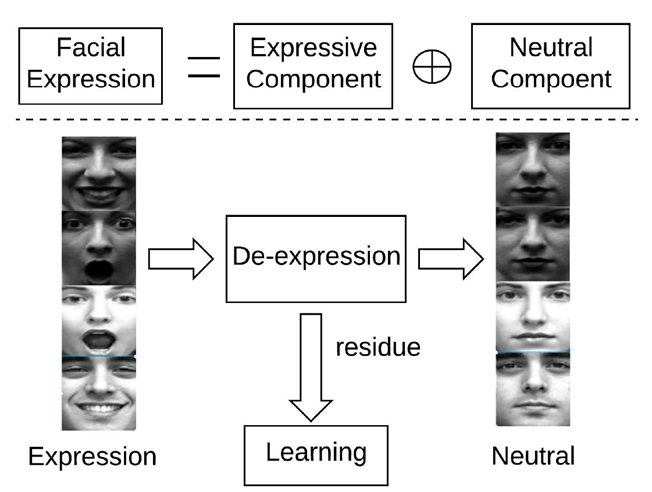
- a facial expression can be decomposed to an expressive component and neutral component[2] 人们可以通过一个参考表情来识别其它表情(这里参考表情用的是中性表情);一个人脸表情可以分为中性部分和表情部分。如图所示。
Network architecture
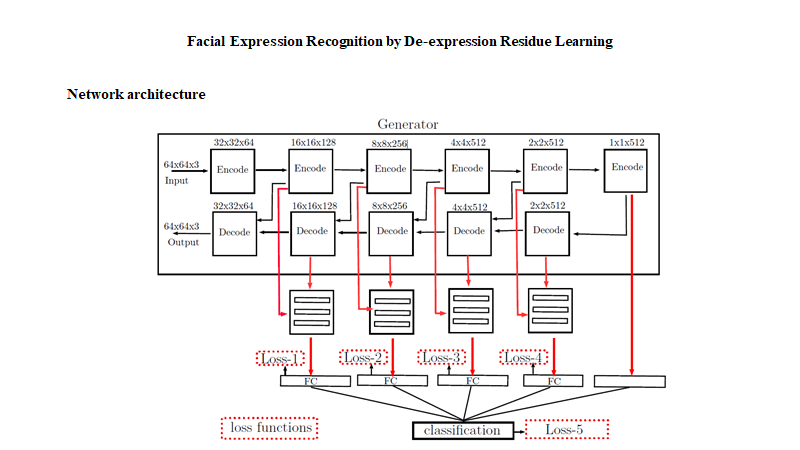 网络结构大体可分为两部分:GAN(Generator)用来生成中性表情,并保存有residue,用于训练学习;第二部分是学习残余特征,然后进行表情分类。 网络结构有很多细节没有体现,比如説学习残余特征的网络结构还有5个损失函数都没详细说明,论文中也没有细说。这里主要是学习的是它分解表情的思想。
网络结构大体可分为两部分:GAN(Generator)用来生成中性表情,并保存有residue,用于训练学习;第二部分是学习残余特征,然后进行表情分类。 网络结构有很多细节没有体现,比如説学习残余特征的网络结构还有5个损失函数都没详细说明,论文中也没有细说。这里主要是学习的是它分解表情的思想。
Generator
cGAN[3]被用来从一个给定的图片生成一个中性人脸表情。 cGAN训练的输入是一个图像对$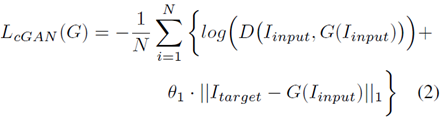 Discriminator的目标函数
Discriminator的目标函数 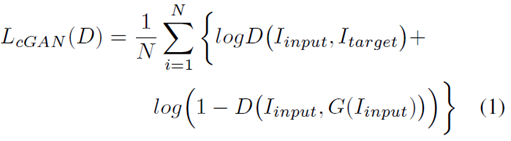 cGAN的目标函数
cGAN的目标函数 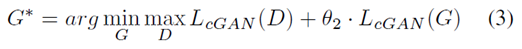
Classification
直接将ganerator的中间层的De-Expression Residue作为CNN分类器的输入进行表情分类。 具体是将Generator中所有尺寸大小一样的特征图合并在一起,分别输入到4个local的CNN分类器
损失函数
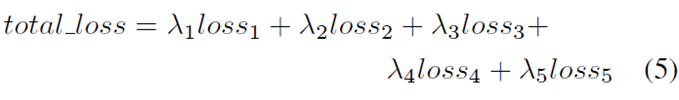 单个loss的系数大小取决于local classifier的表情分类效果
单个loss的系数大小取决于local classifier的表情分类效果 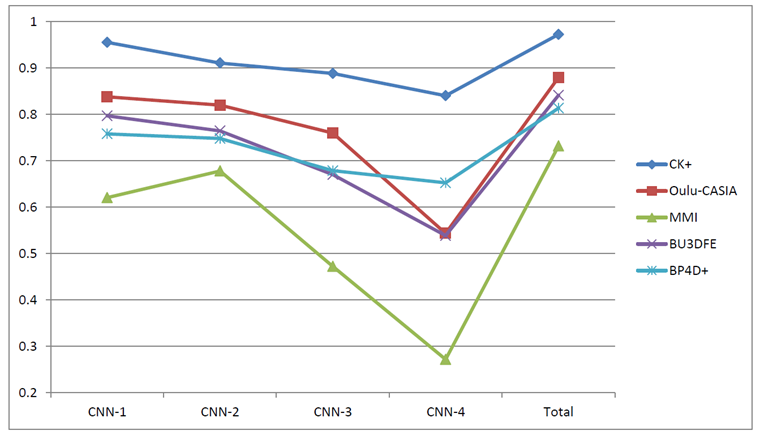
Experiments
Visualization of Expressive Component
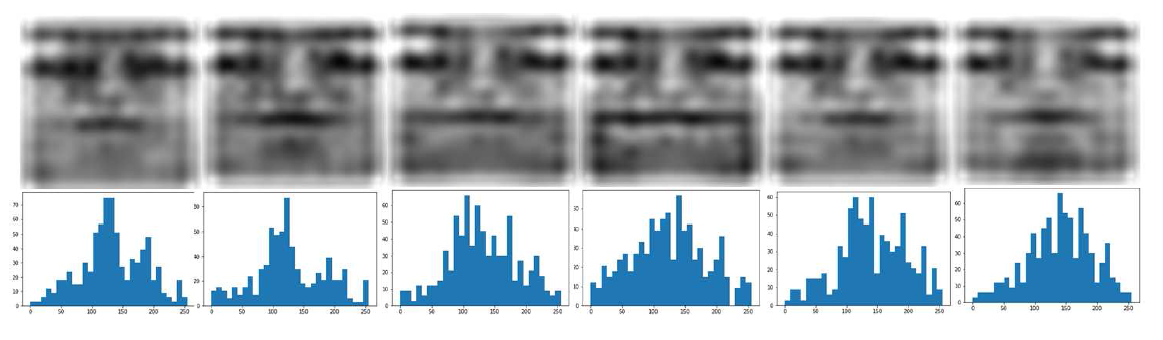 各个表情的残余特征可视化(从左到右是愤怒,厌恶,害怕,高兴,悲伤,惊讶)
各个表情的残余特征可视化(从左到右是愤怒,厌恶,害怕,高兴,悲伤,惊讶)
Visualization of Regenerated Neutral Faces
实验中采用的数据集CK+, MMI, Oulu-CASIA, BP4D+, BU-3DFE , BP4D, BU-4DFE.后2个用于预训练,前面5个方法用于比较实验,体现方法性能 生成器由输入图片得到中性图片 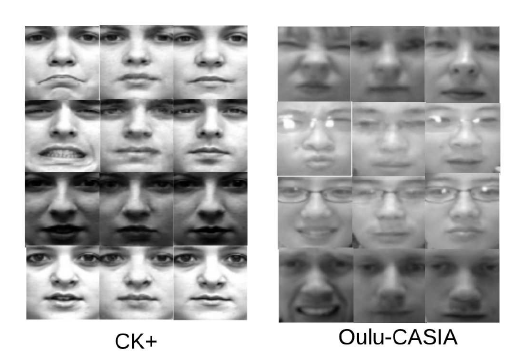
Accuracy on the CK+ database
CK+与各个方法准确率比较 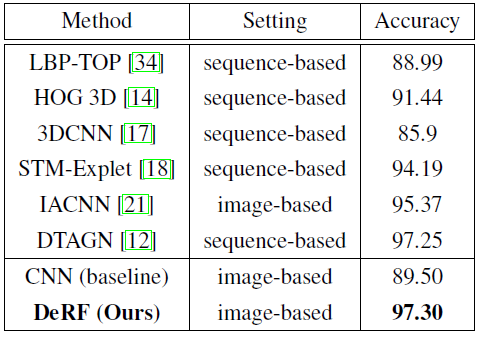 CK+混淆矩阵
CK+混淆矩阵 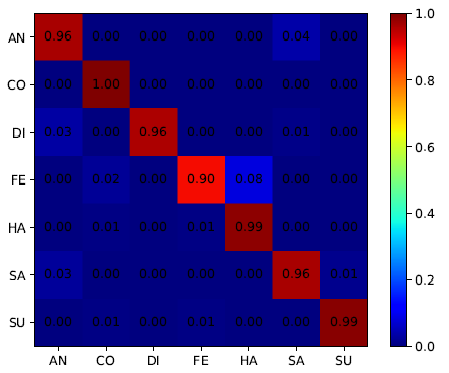 作者后面还在4个数据集上进行相同的实验,都取得比较好的性能,实验结果都处于前2的位置。
作者后面还在4个数据集上进行相同的实验,都取得比较好的性能,实验结果都处于前2的位置。